Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinResearchers Develop Transistor-free Compute-in-Memory Architecture
Using new materials, UPenn researchers recently demonstrated how analog compute-in-memory circuits can provide a programmable solution for AI computing.
In a bid to advance artificial intelligence, researchers from the University of Pennsylvania recently developed a novel compute-in-memory (CIM) architecture for data-heavy computations. CIM has numerous advantages for big data applications, and the UPenn group has taken the first step in producing small, powerful CIM circuits.
In this article, we'll take a deeper look at the principles of CIM and the device physics that enabled the researchers' transistor-free CIM architecture.
Why Compute in Memory?
Traditionally, computing relies primarily on interconnected devices based on the von Neumann architecture. In a simplified version of this architecture, three computational building blocks exist: memory, input/output (I/O) interfaces, and a central processing unit (CPU).

Illustration of the von Neumann architecture, where memory is not co-located with the computational blocks. Image used courtesy of Nature
Each building block may interact with the others based on instructions given by the CPU. As CPU speeds increase, however, memory access speeds can considerably throttle the performance of the overall system. This is compounded in data-heavy use cases such as artificial intelligence, which requires a massive amount of data. In addition, the fundamental speed of light limit can further reduce performance if memory is not co-located with the processor.
All these problems may be solved by CIM systems. In CIM systems, the distance between the memory block and processor is greatly reduced, and the memory transfer speeds may be much higher, allowing for faster computation.
Aluminum Scandium Nitride: Built-in Efficient Memory
UPenn’s CIM system leverages the unique material properties of aluminum scandium nitride (AlScN) to produce small and efficient memory blocks. AlScN is a ferroelectric material, meaning that it may become electrically polarized in response to an external electric field. By changing the applied electric field beyond a certain threshold, the ferroelectric diode (FeD) may be programmed to either a low-resistance or high-resistance state (LRS or HRS, respectively).

AlScN ferroelectric diode illustration showing the two polarization states. Each state exhibits either a low-resistance or high-resistance state, making it an efficient form of memory. Image used courtesy of UPenn ESE
In addition to its operability as a memory cell, AlScN may be used to create ternary content addressable memory (TCAM) cells without transistors. TCAM cells are extremely important for big-data applications since searching for data can be quite time-consuming using the von Neumann architecture. Using the combination of the LRS and HRS states, the researchers implemented an effective tri-state parallel, all without using transistors.
Neural Networks Using Transistor-less CIM Arrays
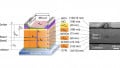
To demonstrate AlScN’s ability to perform CIM operations, the UPenn group developed a convolution neural network (CNN) using a FeD array. The array effectively accomplishes matrix multiplication by summing the output currents created by an input voltage. The weight matrix (i.e. the relationship between the output current and input voltage) may be tuned to discrete levels by modifying the conductivity of the cells. This tuning is achieved by biasing the AlScN film to exhibit the desired conductance.

Neural network formed by an array of AlScN FeDs. By tuning the conductivity of each FeD, the weight/conductance matrix may be modified to accomplish matrix multiplication. Image used courtesy of UPenn ESE
The AlScN CNN successfully identified handwritten numbers from the MNIST dataset using only 4-bit conductivity resolution with ~2% degradation compared to 32-bit floating point software. In addition, the absence of transistors makes the architecture simple and scalable, making it an excellent computational technique for future artificial intelligence applications requiring high-performance matrix algebra.
Breaking the von Neumann Bottleneck
For most of its existence, AI computing has been primarily a software field. As problems become more data-intensive, however, the von Neumann bottleneck has a deeper impact on a system's ability to efficiently compute, making unconventional architectures all the more valuable.
An analog CIM system based on AlScN FeDs removes a major cause of latency for training and evaluating neural networks, making them considerably easier to deploy in the field. The versatility of the AlScN devices integrated with existing silicon hardware may offer a groundbreaking approach to integrating AI into many more fields.