Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinOpen Memory-Centric Architectures Enabled by RISC-V and OmniXtend
This article discusses technologies for memory-centric computing and introduces OmniXtend, a cache coherence protocol.
OmniXtend is a cache coherence protocol that encapsulates coherence traffic in Ethernet frames and can be used to scale memory-centric applications.
Today’s data centers are struggling to keep up with the explosive bandwidth requirements of big data. In many applications, such as artificial intelligence, bioinformatics, and in-memory databases, we commonly run into practical limitations dictated by the maximum available size of main memory. Because this memory is controlled by the central processing unit (CPU), the system architecture is required to conform to the interfaces exposed by the CPU. This effectively fixes the ratio of memory-to-compute in any practical system, which is an impediment to scaling many memory-centric applications.
There are various architectures and interfaces that attempt to circumvent this limitation, but they all have drawbacks. For example, the use of Remote Direct Memory Access (RDMA) architectures requires software to manage the moving of bits from non-volatile storage into and out of main memory, as well as more software to synchronize the distant copies—in other words, to provide coherence to the programmer. The software and network infrastructure needed is burdensome and costly, as are many similar alternative solutions.
New Technologies for Memory-Centric Computing
Several new technologies are enabling architects to rethink memory-centric computing.
The first is the emergence of higher density, byte-addressable nonvolatile memories. These are quickly becoming cost-competitive to DRAM and allow designers to rethink how main memory can be used.
The second advancement is the growth of the programming language P4 and its use in dataplane-programmable Ethernet switches. This new level of flexibility allows architectures to use low-cost Ethernet hardware with completely new protocols.
Lastly, the acceptance and openness of RISC-V. RISC-V is an open instruction set which has spawned numerous different processor microarchitectures. Many of these implementations are open-sourced, including the buses and messaging required for multiple CPUs to share cache and main memory. The cache coherency bus ensures that all caches in the system, whether they belong to CPUs, GPUs, FPGAs, inference accelerators, or other kinds of compute engines, see a synchronized picture of the main memory they share. This makes the software programmer’s task much easier.
OmniXtend as a Cache-Coherent Protocol
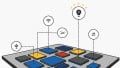
To enable a cache-coherent memory-centric architecture requires the sharing of the cache coherency bus among all existing and future devices which would access main memory. With the existing proprietary ecosystems, such as x86 and ARM, the cache coherency bus is closed. With RISC-V, however, there exist open implementations of on-chip cache coherency buses. With the bus specification available and unencumbered, it can be shared between heterogeneous system components. See an example design in Figure 1.

Figure 1. An example of RISC-V architecture, where open implementations exist.
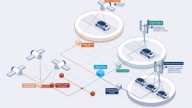
Given the new levels of dataplane programmability of P4 Ethernet switches, it is a logical medium to use for transporting the cache coherency messages. A thorough re-architecting of a compute-and-storage system can now take full advantage of these new technologies and enable continued scaling into the future. To that end, we introduced OmniXtend, a cache coherence protocol encapsulating coherence traffic in Ethernet frames, compatible with off-the-shelf switches. OmniXtend was motivated by the desire to break out of the status quo of prevailing system design and fueled by the urgent need of the RISC-V ecosystem for a common scale-out protocol. A system diagram can be seen in Figure 2.

Figure 2. System diagram
As an open, free protocol available for all to use, OmniXtend leverages the emergence of P4 language and programmable Ethernet switches to transport the cache coherency bus in layer 2 of an Ethernet frame. This innovative, open protocol will seed a robust ecosystem of components that interoperate through an unencumbered and widely available coherence protocol. OmniXtend provides synchronization and consistency in a very efficient fashion, both technically and economically.
OmniXtend builds upon the TileLink coherence protocol, which originated in the RISC-V academic community, to scale beyond the processor chip. OmniXtend uses the programmability of modern switches to enable processors’ caches to exchange coherence messages directly over the Ethernet fabric. OmniXtend allows large numbers of RISC-V and other CPUs, GPUs, machine learning accelerators and other components to connect to a shared and coherent memory pool. Figure 3 shows a high-level block diagram.

Figure 3. A high-level block diagram.
The header format of the OmniXtend packets includes the fields required for coherence protocol operations. The combination of these OmniXtend header fields encodes in every message the necessary information for coherence like the operation type, permission, memory address and data. OmniXtend messages are encoded into Ethernet packets, along with a standard preamble followed by a start frame delimiter. OmniXtend keeps the standard 802.3 L1 frame to interoperate with Barefoot Tofino™ and future programmable switches, by replacing Ethernet header fields with coherence messages’ fields for efficiency.
The OmniXtend protocol shares the coherence policies by a series of permission transfer operations. A master agent (i.e., cache controller) must first obtain necessary permissions on a specific memory block through transfer operations to perform read and/or write operations. None, Read or Read+Write are the possible permissions that an agent can have to work on a copy of a memory block. The protocol initially supports a MESI cache state machine model.
OmniXtend has already been implemented in FPGA boards and a Barefoot Tofino switch.
The Xilinx VCU118 FPGA evaluation board has been configured to run a SiFive RISC-V U54-MC Standard Core with OmniXtend protocol. Two of these FPGA boards are connected to a top of rack (ToR) Barefoot Tofino switch via SFP+ connectors. The RISC-V cores on each VCU118 board issue random read and write requests in the coherent mode for different memory block sizes hosted on the other board. The OmniXtend protocol ensures the processor coherently reads the memory locations. See the demonstration in Figure 4.

Figure 4. A demonstration of OmniXtend.
OmniXtend's Performance
To see how OmniXtend performs, various latency measurements have been taken in Figure 5. Recognize that the RISC-V OmniXtend CPU in the FPGA only runs at 50Mhz. As the test data pool size increases, so does the average memory access latency. This is because at some point most of the data is fetched from L2 cache and then from main memory. When remote memory is accessed, there is additional latency from serializing the coherency traffic and the delay through the Ethernet switch. The latency will be reduced further once the OmniXtend protocol is implemented in a dedicated silicon device.

Figure 5. Various latency measurements to show OmniXtend's performance.
OmniXtend is a move toward enabling a very large number of compute nodes to connect directly to coherent shared memory over commodity Ethernet fabric. OmniXtend is the first cache coherent memory technology providing open-standard interfaces for memory access and data sharing across a wide variety of processors, FPGAs, GPUs, machine learning accelerators, and other components. Moreover, the programmability of OmniXtend capable switches allows any desired modifications to coherence domains or protocols to be deployed immediately in the field, without requiring new system software or new ASICs. OmniXtend will accelerate innovation in data center architectures, purpose-built compute acceleration and CPU microarchitectures.