Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinUsing a Fabric Architecture, Startup Claims Most Energy-Efficient Processor
With its E1 processor announced today, Efficient Computer is hoping to usher in a new era of general-purpose computing efficiency.
Today, Efficient Computer has formally released their Electron E1, a general-purpose processor that departs radically from the industry’s longstanding reliance on von Neumann architectures. Aside from being Efficient’s first standalone hardware release, the chip is noteworthy as the company is calling it the “world’s most energy-efficient general-purpose processor”.
All About Circuits had the chance to talk to Brandon Lucia, CEO/Co-Founder of Efficient Computer, to learn more about these claims firsthand.
The Electron E1
When building the Electron E1, energy consumption was priority number one. As Lucia tells us, “Every time there was a design choice, we opted for ‘let’s minimize energy again.’ The only thing we cared about was minimizing energy.”
To this end, E1 is built on a proprietary spatial dataflow architecture called the Fabric, which eliminates the overhead associated with instruction fetch, decode, and register file movement. According to Efficient, this design enables unprecedented energy efficiency of up to 1 trillion 8-bit integer operations per second per watt (1 TOPS/W) in a chip that retains full software programmability and general-purpose utility.

The Electron E1 represents a departure from traditional von Neumann architecture.
According to Efficient’s internal silicon measurements, the E1 routinely delivers between 10x and 100x improvements in energy efficiency compared to established low-power processors. Benchmarks using standard C code demonstrate up to 350x reductions in energy usage for equivalent workloads.
The Fabric architecture achieves this by spatially mapping operations across a tiled grid of compute elements, each of which activates only when its inputs are available. This mechanism stands in contrast to the continuous instruction cycling and indirect data movement that dominate traditional CPU pipelines.
“If you tell a computer to do X plus Y, it turns out that between 95 and 99% of the energy consumed goes into instruction supply, decode, pipeline reconfiguration, and operand supply. Only 1 to 5% is actually used doing the add,” says Lucia.
The Electron E1 also supports full-stack programmability where conventional code is compiled into dataflow graphs that are placed across the Fabric. In the process, the system remains deterministic and statically scheduled, with compiled programs persisting in place for up to 100 million cycles.
E1 Hardware Specifications and Fabric Capabilities
At the physical level, the Electron E1 is fabricated with a standard BGA package and incorporates on-chip memory and peripheral interfaces to minimize external dependency. It contains 4 MB of MRAM for non-volatile code and data storage, along with 3 MB of SRAM and 128 KB of banked cache. The chip supports six instances each of QSPI, UART, SPI slave, and I2C master interfaces, alongside 72 GPIO lines and a real-time clock.
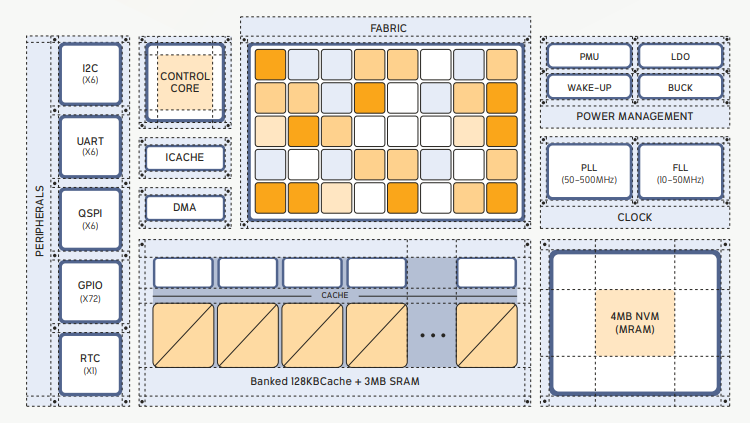
Block diagram of the Electron E1
In performance terms, the E1 operates in two selectable modes: a low-voltage mode achieving 6 GOPS with a 25 MHz Fabric clock, and a high-voltage mode achieving up to 24 GOPS at 100 MHz. Dynamic power modes, including sleep and deep-sleep, are supported via a programmable wake-up controller and integrated buck and LDO regulators.
The chip's active scalar RISC-V core can enter a power-down state while the Fabric continues execution.
Operating from a 1.8 V supply with an internal logic voltage range of 0.55 V to 0.8V , the E1 is rated for industrial temperature ranges from -40°C to 125°C.
Compiler Strategy Reduces Developer Friction
Alongside the E1, Efficient has launched the first public release of its compiler toolchain, effcc, which abstracts the unique hardware under a standard development interface. Built on LLVM and MLIR, the compiler accepts standard C code and integrates into existing developer workflows with minimal changes. Developers can use common build tools like Make and CMake, as well as editors such as Visual Studio Code, by simply pointing to the new compiler binaries.
This maintains compatibility with debugging tools and workflows engineers already understand. As Lucia puts it, “You just use effcc and it does exactly like Clang on the front end… If you use VS Code, Make, or CMake, you just make it aware of where our compiler is and boom—everything works.”
The compiler’s frontend uses Clang, and, in the middle-end, Efficient converts this input into an intermediate representation tailored for the Fabric. Advanced optimization routines, including an AI-based scheduling framework called the Modular Optimization Framework (MOF), analyze the structure of the code and map it efficiently across the spatial grid. This includes automatic routing of instruction outputs to downstream tiles and optimization of dataflow paths to minimize latency and power consumption.
With these tools, developers can simulate execution on a web-based playground, which includes an interactive visualization of how instructions propagate through the Fabric. The company emphasizes a “two-minute to Hello World” development experience that all-but eliminates the learning curve associated with new platforms.
Designed for Embedded AI and Beyond
According to Efficient, the E1 is best suited for embedded and edge AI workloads that typically suffer under the limitations of current CPUs and narrow-purpose accelerators. By offering accelerator-class energy efficiency with CPU-grade programmability, Efficient places the E1 between general-purpose computing and dedicated silicon for AI inference.
Whereas standalone accelerators isolate the dense matrix-multiplication core of a machine learning pipeline, the E1 can handle upstream signal processing, sensor fusion, and downstream analytics or control logic on the same chip.
Efficient is already sampling the E1 with early-access customers, and is working with partners across industrial and aerospace verticals. The upcoming Photon P1, a higher-end successor to the E1, will extend the architecture’s applicability to larger-scale edge compute scenarios and possibly into the low-end data center tier. As Lucia tells us, “Our architecture has this scalability property and this efficiency property, and that’s really fundamental.”
“My vision for the company is that we start today in the embedded space with E1, and we can scale all the way up to the Edge, the Cloud, and ultimately to the data center.”
All images used courtesy of Efficient Computer.