 Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinUnderstanding Methods to Automate Data Quality Management
Automated data testing is critical, especially in this era of huge datasets. Learn the different methods for testing data quality and how SaaS tools and machine learning can smooth the way.
The purpose of data validation is to ensure a certain level of quality of the final dataset. A growing number of businesses are setting up modern data stacks to become more data-driven organizations. Raw data, raw events from apps, feeds from third parties, and more refined, usable data all end up in a data warehouse.
From there, data is relied upon to ultimately make informed business decisions, create products, and grow faster. However, if the data itself is unreliable or of poor quality, any decisions made from it will inevitably be as well. This underscores the importance of thorough and high-quality data validation tools.
A Dynamic Analysis Approach
Sifting through vast stores of data is a behemoth task where a more dynamic analysis approach is generally much more fruitful than static ones with fixed rules and specified ranges. This strikes a balance between the computational resources expended on data quality management and the effectiveness of the data quality management system.
In this article, we’ll discuss some approaches for unsupervised data monitoring and how automating data quality management can be accomplished with SaaS tools to expedite the process of data scrubbing and optimize the effectiveness of the data team.
Methods of Measuring Data Quality
Given the importance of data-driven decisions in modern business, it is imperative to employ mechanisms to ensure the integrity and accuracy of data within the data warehouse. In practice, there are four principal approaches to testing data: fixed rules, specified ranges, predicted ranges, and unspecified testing. These approaches fall into two broad categories of static and dynamic testing (Figure 1).

Figure 1. Approaches to testing data fall into two broad categories: Static and dynamic testing.
Static testing relies on specified parameters such as fixed rules and specified ranges. Fixed rules make a statement in absolute terms about a dataset. For example: “this column is never NULL,” which applies to situations in which data must be perfect in a predetermined manner.
Specified ranges require a computed number to be within a predetermined interval, such as the mean of a column. Static tests are an effective way of detecting abnormalities in cross-sectional data and detecting when key metrics exceed a specified range: this requires detailed knowledge of how the dataset behaves. Over-reliance on static testing methods can lead to poor test coverage, and the maintenance burden can rapidly become unsustainable.
The unpredictability of evolving datasets necessitates methods beyond static testing to ensure the maintenance of high-quality data. Dynamic testing methods harness predicted ranges, thereby allowing for normal fluctuations in trend or seasonality or events like holidays and the accurate prediction of a calibrated interval of possible outcomes based on historical variance.
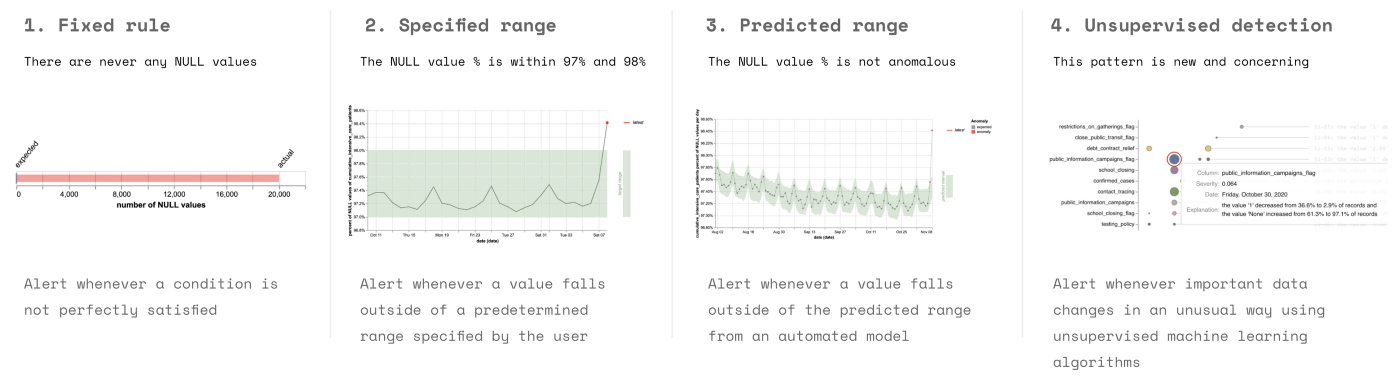
Figure 2. The four approaches to data testing: fixed rules, specified ranges, predicted ranges, and unspecified testing. (Click image to enlarge)
An example of one of these strategies is time series detection, which uses historical data to estimate the common trends in data. This establishes a baseline for normal behavior and recognition of normal deviations. The use of historical data and predicted ranges prevents reactive manual adjustments of parameters, which can result in missing erroneous data later on.
The most sophisticated approach to testing data is unsupervised detection. This technique surveys important datasets for anomalous changes using machine learning (ML) algorithms. The only requirement for this surveillance method is that the user specifies which data is important. The algorithm will then generate an alert when this important data changes unexpectedly. Figure 2 shows a breakdown of the four types of approaches: fixed rules, specified ranges, predicted ranges, and unspecified testing.
The Testable Aspects of Data Quality
Data can be validated by applying queries to several different aspects of the data within the dataset. Missing data is a common error that arises in complex datasets, so validation of existence ensures that a dataset is complete. If all of the data is present, then the format and how precise the data value needs to be—the number of decimal points, for example— can be subjected to data validation.
Uniqueness of data is an important aspect of data validation, and time-series or cross-sectional datasets will have different requirements in identifying duplicate data entries. Validation of both range and relation can identify extreme data values and values that do not have the expected stochastic relation with other variables.
ML can be harnessed to provide unsupervised detection of anomalous metrics within a dataset. The number of rules that are required to monitor the tables contained in a data warehouse rapidly increases to the point that the manual, human management of the data is unsustainable.
The four domains that are used by Anomalo to provide automated data validation are summarized in Table 1. If there is a sudden change or anomaly within these domains, a report is generated in the user interface, and the relevant team is notified.
Table 1. Parameters used by Anomalo’s data validation ML algorithm
| Data Freshness | Is the data arriving in the data warehouse at the expected time? | Ensures data arriving is the most up to date |
| Data Volume | Has all of the data arrived in the data warehouse or is there missing data? | Detects and notifies of a sudden drop in the quantity of data arriving in the data warehouse compared to normal |
| Missing Data | Is there a drop in segment records, an increase in null values, or an increase in 0 values? | Detects missing data values and gives an indication of the extraneous nature of the anomaly by stating the number of satisfactory runs prior to anomaly detection |
| Table anomalies | Are there anomalous records within a data warehouse table according to unsupervised ML algorithms? | Detects sudden spikes in NULL values and anomalies, the severity of which is graded based on a learned threshold for the table |
Rooting Out the Underlying Data Issue
Highlighting that there are errors in your data is an important part of data validation, but the next crucial step in ensuring the integrity of the data is correcting the error through a root cause analysis. Running an automatic root cause analysis can efficiently reduce costs by resolving the issues flagged up in the data validation process. Root cause analyses can be carried out manually, or they can be done automatically using ML algorithms.
Typically, analysts will initially investigate records that have NULL values, resulting in the analysis of a biased and unrepresentative portion of the overall dataset. Although simple validation rules can be used to identify the reason behind NULL values in a given segment of a table, to do so for every section in a table is extremely time consuming and rapidly becomes infeasible.
Alternatively, a ML algorithm, such as a decision tree algorithm, can be applied to a data sample to identify the good and the bad data. Although this can help to understand the decisions separating the good and the bad data, the results can overfit the data. Producing a functioning model requires human intervention resulting in high costs when applied at scale.
Fully automated root cause analysis using ML algorithms can greatly increase the speed at which issues are identified and resolved. Robust analytic systems, for example, might sample the data, analyzing every segment independently, and then cluster the segments together that are highly related.
By computing the percentage of bad and good rows in a segment, identifying the areas with higher prevalence of bad rows can localize the segment containing the issue. Fully automated root cause analysis allows for diagnosis and resolution of data quality failures more quickly, leading to greater test coverage and more rapid resolution of failures.
Streamline by Using Cloud-based SaaS tools
Software as a service (SaaS) are tools that may be accessed through a cloud-based system. Accessing SaaS tools requires only a web browser, an internet connection, and a subscription to the desired service. SaaS tools can help to automate manual tasks, improve customer satisfaction as well as cut costs and improve data security.
Using SaaS tools, such as Anomalo, for data validation can dramatically improve and simplify the process of data validation while reducing costs and improving data quality and security for businesses.
Anomalo ML Models Improve Data Quality
Data is the backbone of many modern organizations. However, the quality of the data relied upon is often seen as an afterthought. This can lead to the issue of data teams scrambling to root out major data issues only after they have cropped up, dropping the total efficiency and effectiveness of the team. And, the more data that is collected and used, the more data quality issues will be found.
With that in mind, organizations that want to continue to be data-driven will almost inevitably require a streamlined method of data quality monitoring. Much of this can be accomplished by following standard best practices for monitoring data quality, where much of this process can be done unsupervised.
Anomalo uses ML models to predict, infer and evaluate the data quality of a data warehouse with relative ease by ensuring data freshness, the correct data volume, checking for missing data, and noting any table anomalies. This approach enables a fully automated approach to identifying common data issues.
All images used courtesy of Anomalo
Related Content












