Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinDesign Implementation in the Xilinx Vivado Design Suite
This article will look at the techniques that Vivado employs to accelerate design implementation.
This article will look at the techniques that Vivado employs to accelerate the design implementation.
In a previous article, we discussed some of the techniques that Vivado uses to accelerate the “time to integration” stage of the design process. This article will look at the techniques that Vivado employs to accelerate “design implementation”.
The Vivado Analytical Place and Route
The place-and-route (P&R) in FPGA design is a stage which finds the real physical design that will be realized inside the FPGA chip. As the name suggests, the place-and-route has two steps: placement and routing. The placement determines which block within the FPGA chip should be used to implement a given logic element of the design. The routing step determines which routes (wires in the FPGA) should be used to connect the placed blocks to each other. Many traditional FPGA design tools rely on an algorithm called “simulated annealing” to perform place-and-route. The basic concept of this algorithm is shown in Figure 1.

Figure 1 Simulated annealing-based P&R. Image courtesy of Xilinx.
As you can see, an initial random point is chosen as the placement solution. Then, the solution space around this initial random point is explored and a cost function, usually timing, is examined. If the local move reduces the cost function, the new point will be used as the start point for the rest of the algorithm. As shown in the figure, sometimes the obtained placement is not routable and, hence, we may have to move in a direction that actually increases the cost function.
With the simulated annealing, the initial point and the subsequent local moves have a random nature. That’s why the traditional FPGA design tools that use this algorithm cannot have a predictable run time for the P&R stage. Moreover, note that, in the example of Figure 1, the random local movements have not yield the optimal solution. It has only found a local minimum of the cost function (shown by “Best Solution Found” in the figure). Besides, this optimization example is one dimensional and tries to minimize only one cost function.
To circumvent these problems, the Xilinx Vivado has developed an analytical place-and-route engine that uses a large mathematical equation to minimize a multi-variable cost function. This is illustrated in Figure 2.

Figure 2 The analytical P&R engine of Vivado. Image courtesy of Xilinx.
As shown in the figure, the cost function is three dimensional and attempts to find a global minimum for timing, wire length and congestion of the design. This analytical algorithm allows the tool to have a very predictable run time in the P&R stage. Figure 3 below compares the run time of Vivado with another competitor tool. In this figure, the horizontal axis represents the design size. As you can see, the run time of the Vivado is not only much smaller than the traditional tool but also has a very predictable manner and grows linearly with the design size.

Figure 3 Design tool run-time vs design size. Image courtesy of Xilinx.
The following figure compares the Vivado optimization algorithm with the Xilinx ISE and another FPGA design tool. As you can see, the run-time of Vivado is much more predictable than that of ISE. It’s worth to mention that traditional tools have poor results as the design size approaches one million logic cells; however, Vivado can handle 10M+ logic cells with predictable results.

Figure 4 Vivado vs other tools. Image courtesy of Xilinx.
The “Out-of-Context” Flow
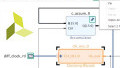
Vivado can implement modules of a design independently. Such modules are said to be implemented out-of-context (OOC). This capability of Vivado allows us to verify and implement the important blocks individually. Then, the netlist obtained from the out-of-context implementation will replace the HDL version of the OOC block when implementing the top-level module. In this way, we can implement a particular module in the OOC mode and avoid consuming additional CPU cycles for that module when implementing the top-level module.
The OOC implementation helps us to verify a module before placing it in a larger design which can have a much longer run time. Moreover, we can implement a module in the OOC mode once and import the result once or multiple times in any of our future projects. Since no additional CPU cycles are required for the OOC blocks, we can significantly accelerate the implementation time of our projects. This netlist reuse strategy is illustrated in Figure 5.

Figure 5 Image courtesy of Xilinx.
Incremental Implementation
With today’s algorithms, we may have to wait several hours before an FPGA design tool can place-and-route our circuit. However, sometimes, just before the tool finishes its work, we remember that we have made a small mistake in our code. For example, instead of using a particular signal, we have used its complement or, maybe, we have forgotten to change a parameter on a Mixed-Mode Clock Manager (MMCM). For such small changes, we may be able to use the incremental implementation feature of Vivado to modify the placed-and-routed design without going back to the usual synthesis and implementation stages. The design flow of incremental compile is shown in Figure 6.

Figure 6 Vivado incremental compile flow. Image courtesy of Xilinx.
As you can see, the first run (on the left) is used as a reference for the second run (on the right) in which the design is modified. Incremental implementation is an incredible flexibility that allows us to modify the placed-and-routed design directly and “quickly” apply small changes.
In this article, we only briefly reviewed some of the important features of the Xilinx Vivado that accelerates the time to implementation of a design. However, there are several other features of this software that may interest you. For example, Vivado supports a powerful interpreted programming language called Tcl which stands for Tool Command Language. With this capability, you’ll have control on almost every aspect of the software. You can write a Tcl script to automate repetitive operations that otherwise can take a lot of your time. Or you can write a script to perform multiple calls to the Vivado optimization functions that are available in different design stages.
Here, we looked at some of the advantages of the Vivado Design Suite over the traditional FPGA design tools. If you’re familiar with similar capabilities in other tools, please share your experiences with us in the comments below.
Related Content