 Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinArm Axion Heads Google’s 8th-Gen TPUs as Cloud Pivots to Agentic AI
Google Cloud split the TPU line into training and inference variants, with Arm Neoverse-based Axion CPUs as the host across the stack. Arm also rolled out Performix, a free performance toolkit aimed at the silicon's growing developer base.
At Google Cloud Next, Google unveiled its eighth-generation TPUs—TPU 8t and TPU 8i—alongside an expanded role for Arm's Axion CPUs as the host processor across the new fleet.

Google Cloud's eighth-generation TPUs come in two distinct systems: TPU 8t and TPU 8i.
Separately, Arm announced Performix, a free performance analysis toolkit for Arm-based servers. Both moves are framed around a single workload shift: agentic AI systems that orchestrate continuous chains of reasoning, tool calls, and retrieval rather than serving one-shot model queries.
TPU 8t and 8i: One Generation, Two Architectures
Where prior generations relied on a single die for both training and serving, the eighth generation splits the TPUs in two.
TPU 8t targets large-scale pre-training and embedding-heavy workloads, scaling to 9,600 chips per superpod across a 3D torus interconnect. Each chip carries 216 GB of HBM at 6,528 GB/s, 128 MB of on-chip SRAM, and 12.6 peak FP4 PFLOPs. A dedicated SparseCore offloads the irregular memory accesses behind embedding lookups, keeping the matrix-multiply units from stalling on data-dependent collectives, and a new LLM Decoder Engine accelerates autoregressive paths.
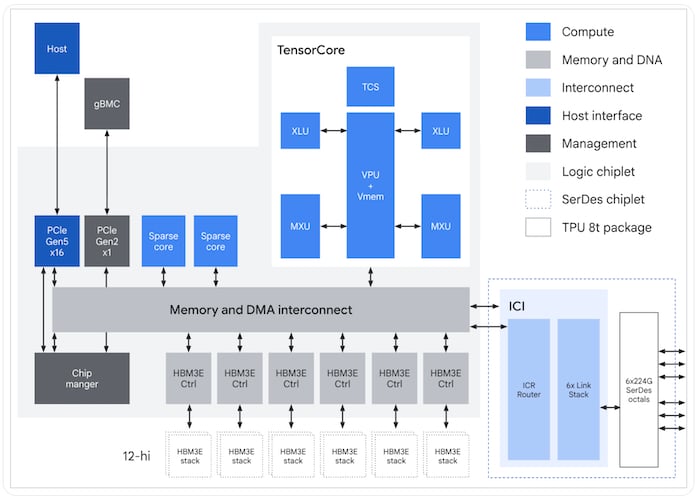
TPU 8t ASIC block diagram.
TPU 8i is the inference and reasoning sibling, scaling to 1,152 chips per pod on a new "Boardfly" topology that Google built specifically to reduce network diameter for the all-to-all traffic typical of mixture-of-experts routing. The chip pairs 288 GB of HBM and 8,601 GB/s of bandwidth—roughly 1.3 times TPU 8t's HBM bandwidth—with 384 MB of on-chip SRAM, three times the previous generation. That SRAM jump is load-bearing for serving long-context decoding, since the KV cache can sit on silicon rather than spilling to HBM. A new Collectives Acceleration Engine handles synchronization across the Boardfly fabric.
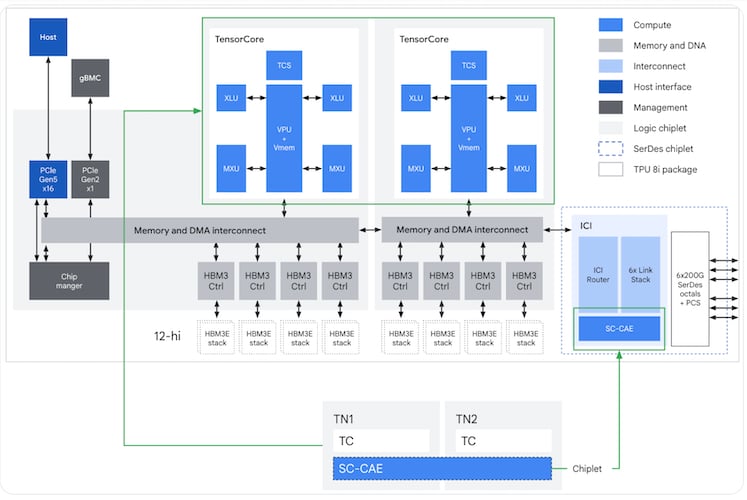
TPU 8i ASIC block diagram.
Google quotes a 2.7 times training price-performance gain for TPU 8t over the seventh-generation Ironwood TPU and an 80% inference price-performance gain for TPU 8i, with both chips delivering up to 2x better performance-per-watt. JAX, PyTorch, and Keras code that already runs on Ironwood ports across.
The system-level tying everything to Arm is the host CPU. For the first time, both TPU 8t and TPU 8i ship with Arm Axion, Google's Neoverse V2-based custom CPU. That’s a decisive choice for agentic workloads because CPU tasks like data preparation, tool calls, and orchestration logic determine how often the matrix engines run.
Axion's Expanding Footprint at Google Cloud
The TPU header role lands alongside a broader push for Axion across Google Cloud's general-purpose tiers. C4A virtual machines and the new C4A Metal bare-metal instances target latency-sensitive AI inference on general compute, while N4A, the most recent Axion addition, covers cost-sensitive scale-out workloads such as web services, APIs, and data pipelines.

C4A, Google Cloud's first Axion processor.
Google also tied Axion to its new GKE Agent Sandbox, a gVisor- and Kata Containers-based environment for safely running untrusted code generated by agents. The sandbox is meant to give agents a place to spin up short-lived containers, execute tool calls, and tear them down within latency budgets that x86 hosts have struggled to meet at concurrency.
Loveholidays, a European travel platform, was cited as an early production user, running petabyte-scale embedding and inference workloads on C4A, where the use of accelerators was cost-prohibitive.
Profiling for the Agentic Stack
Arm's second announcement, Performix, is a free toolkit for performance analysis on Arm-based servers, built to plug into agentic development workflows.
It collects runtime data directly from Arm silicon—counters, traces, and microarchitectural events—and delivers it through pre-configured "recipes" intended to be readable by both human engineers and AI agents. Outputs are structured so they can feed back into automated tuning loops, which matters once optimization itself is partially delegated to agents.
For hardware designers building or buying Arm-based platforms, Performix is the first vendor-supplied profiler for the full Neoverse stack, from cloud silicon to next-generation parts like the Arm AGI CPU.
Microsoft, MongoDB, Redis, and SAP are launch partners. Arm reports that 50% of CPU compute shipped to top hyperscalers in 2025 was Arm-based.
All images used courtesy of Google Cloud.
Related Content












