Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinPhysically Unclonable Functions: Classification, Evaluation, and Tradeoffs in PUFs
In this article, we’ll take a deeper look at how PUFs are classified, the attributes that make a “good” PUF, and design tradeoffs.
In the previous article, we discussed physically unclonable functions (PUFs) and why they’re a powerful tool for security on the silicon level. PUFs have become an extremely popular security option for IC designers, and, like any budding field, it has evolved and grown in many different directions.
For this reason, it is useful to be able to classify different types of PUFs from one another. In this article, we’ll discuss how PUFS are characterized, evaluated, and what makes one better than another for a given application.
What Makes a “Good” PUF?
The first thing we need to consider when classifying and using PUFs is: what are the metrics that actually define a PUFs performance?
Generally, a PUF’s performance is measured by its level of robustness (stability over time), uniqueness (no two PUFs are the same), ease of evaluation (to be feasibly implemented), difficulty to replicate (so the PUF cannot be copied), and difficulty to predict/randomness (so the responses cannot be guessed).

Figure 1. Different PUF characteristics can be mathematically quantified by a series of statistical tests. Image from Heinski et al
An Example: Measuring Uniqueness and Randomness
While some metrics are easier to evaluate than others, each of these metrics has a series of statistical tests that can be performed to gauge performance. An example test for uniqueness and repeatability is evaluating the Hamming distance. If we compare two binary sequences of equal length, the Hamming distance is simply the the number of bit positions in which the two bits are different. For a single PUF device, the Hamming distance for repeated outputs should be low - the output code is the same every time. However, when comparing the binary output from two different PUF devices, we would like the Hamming distance to be high.

Figure 2. A PUF’s unique response is expected to be repeatable on the same IC but different from other ICs. The above image shows a real world PUF which behaves close to, but not perfectly, like an ideal PUF. Image from Tanamoto et al
To empirically measure this, an engineer would provide two different PUFs with the same challenge multiple times and record the response each time. To calculate the inter-chip variation, the engineer would calculate the Hamming distance from all of the responses from a single PUF. To calculate the intra-chip variation, the engineer would calculate the Hamming distance between the responses from the different PUFs.
An ideal PUF is repeatable, meaning that every time we provide it a challenge we’d expect the same response. This would correspond to a Hamming distance of 0. An ideal PUF is also unique, meaning that if we provide it with a challenge, it will produce a statistically different response than the same challenge on a different IC. If the PUF is truly random and unique, the intra-chip variation should be 50% on average.
Weak vs. Strong PUFs
Another classic way that PUFs are classified is in terms of the strength of their implementation.
Commonly divided into two categories, strong and weak, PUFs have their strength classified by the number of challenge-response pairs (CRPs) that a single device can generate. This is also related to the device size and scaling. In the context of PUFs, scaling refers to the relationship between the size of the PUF device and the number of CRPs that it can generate.

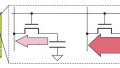
Figure 3. Weak PUFs require an extra layer of key obfuscation due to their limited number of CRPs. Image from Marconot et al
A weak PUF is one that supports a small number of challenge-response pairs. Additionally, the number of CRPs that a weak PUF can generate may scale only linearly or as a polynomial function of the PUF size. In this type of PUF, an attacker can conceivably read the full set of CRPs if they have physical access to the device. Often, weak PUFs are used for key storage and entity authentication.
A strong PUF is a PUF that scales in such a way that it can support a very large number of CRPs. The number of CRPs may grow exponentially as a function of the size of a strong PUF. The important distinction is that they can support so many CRPs that, even if an attacker had access to the device, they would be unable to record all of them. With so many CRPs, each pair only needs to be used once. Strong PUFs protect against attacker eavesdropping and even enable PUF based communication protocols.
A Quick Note: PUF Tradeoffs
Obviously achieving an ideal PUF is not realistic because, like all things engineering, tradeoffs must be made in the implementation of PUFs. Notably, a designer is often concerned with area, cost, and power consumption—all of which play into PUF performance.

Figure 4. Researchers have found a tradeoff between PUF delay and power consumption, highlighting the many tradeoffs PUF engineers must consider. Image from Wu et al
A higher power PUF will certainly exhibit better immunity to noise and bit errors. But, if the circuit is inefficient, it may be prohibitive for use in power-constrained devices. A PUF with a larger area will likely be able to produce a larger amount of CRPs, pushing it deeper into the classification of a strong PUF. On the other hand, silicon real estate is expensive, and more area requires more money.
Generally in PUF design, priority must be given to one of the aforementioned constraints depending on the objectives or constraints of the use case. An engineer will have to weigh general circuit specifications, like power and area, with PUF specific statistical specifications, like randomness, uniqueness, and reliability, to fairly evaluate and compare the PUF's utility in their specific application.
Many Considerations
PUFs are a seemingly simple concept, but the actual design and implementation require an intense amount of evaluation and tradeoffs.
Hopefully, a better understanding of the metrics, evaluation techniques, classification, and design tradeoffs will provide a deeper insight into the intricacies of this field.