 Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinPrinciples of Cache Design
This article will examine principles of CPU cache design including locality, logical organization, and management heuristics.
This article will examine principles of CPU cache design including locality, logical organization, and management heuristics.
The 1980s saw a significant improvement in CPU performance, though this was hampered by the sluggish growth of onboard memory access speeds. As this disparity worsened, engineers discovered a way to mitigate the problem with a new design technique—caching.
This article will help you learn more about what caching is, how it works, and how to design a CPU cache.
What Is a CPU Hardware Cache?
A CPU hardware cache is a smaller memory, located closer to the processor, that stores recently referenced data or instructions so that they can be quickly retrieved if needed again. By reducing costly reads and writes that access the slower main memory, caching has an enormous impact on the performance of a CPU. Virtually all modern processors employ some form of caching.
The first caches were off-chip, or external. These were soon replaced by on-chip cache memories typically made from SRAM. To improve performance further, these on-chip caches were split into instruction and data partitions.
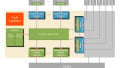
Figure 1 shows an example of partitioning.

Figure 1. The Intel 80486 used a general cache, while its successor, the Pentium P5, had a partitioned cache (bus widths have been omitted)
Cache partitions led to the birth of multi-level cache hierarchies, where processor cores would have their own small, private cache (L1) that sat above a larger shared cache (L2), with some processors including a third cache level (L3) and occasionally a fourth (L4).
Locality (AKA How Does Caching Work?)
Why does caching work? Caching works via the principle of locality of reference. Locality of reference refers to the tendency of a processor to access the same memory locations as it runs an application. Because these memory accesses are predictable, they can be exploited via caching.
Locality is typically divided into two subsets—temporal locality and spatial locality—and sometimes a third, known as algorithmic locality.
Temporal Locality
Temporal locality refers to the reuse of specific data items within a short time frame. This relies on the fact that programs running on a processor tend to make use of the same variables and data structures within a short time window. After fetching an item from main memory and storing it in cache, any subsequent calls for that data can be done much faster.
Spatial Locality
Spatial locality refers to the tendency of data items that will be needed soon to reside in memory locations near or adjacent to items that are needed now. This can be the result of either programmers or compilers clustering items in memory.
For instance, applications that make use of arrays (a type of data structure) will store the elements of the array in adjacent memory locations. By caching the data items next to the one currently being used, the processor can quickly access those adjacent items when necessary.
Algorithmic Locality
A less frequently discussed type of locality is algorithmic locality. Algorithmic locality is the tendency of applications to perform operations on related data items though not in any short time period and despite the fact that the items are not near each other in memory.
Applications using a linked list (another type of data structure) may exhibit this behavior. This type of locality could appear in graphics processing or iterative simulations.
Logical Cache Organization
How and where a cache stores and retrieves data is based on the way that cache is organized. This is called the logical organization of the cache. Determining what gets stored is controlled by management heuristics built into the cache, but it is also heavily influenced by the logical organization. Thus, how a cache is laid out plays a huge role in its performance.
There are three main ways to organize a cache:
- Fully associative
- Direct-mapped
- Set associative
Cache Blocks
When a CPU needs to access an item in main memory, it uses an address to locate that item. A CPU hardware cache typically works transparently, meaning without the programmer having to acknowledge the cache in any way. Thus, the address used to access memory is first handled by the cache. This address is used to identify whether or not a data item is located in the cache.
The term “cache hit” indicates that the data item was found in the cache, and “cache miss” indicates that it was not.
Caches are organized into groups of data called cache blocks. Each address is partitioned into a number of bit fields so that the correct cache block can be identified. These fields are the cache tag, set number, and byte offset. Figure 2 shows an address split into fields that the cache can interpret.

Figure 2. Addressing a cache block
When a CPU cache is given an address, it breaks this address into the necessary fields and begins checking its cache entries. A cache entry consists of a cache tag (here labeled tag) and a cache block (labeled data).
- The cache tag is an identifier that signals which cache block is being referred to.
- The cache block is the actual data stored at that tag and represents a block of items from main memory. To get to individual words within that block, an offset is used.

Direct-Mapped
In a direct-mapped cache, the cache entries are organized into a number of sets. The set number from the address is used to index each set of entries. Once the set is identified, the cache tags are compared. If they are a match, this is a cache hit and the specified data is output.
The key to understanding direct-mapped caches is that each set will only have a single cache entry. This makes the direct-mapped cache incredibly fast while consuming minimal power.

Figure 3. Adirect-mapped cache
Since each set can only contain one entry, direct-mapped caches do have higher contention rates, meaning multiple data items will want to be stored at the same location. This results in cache misses. One way around this problem is to use a fully associative cache.
Fully Associative
A fully associative cache is the opposite of a direct-mapped cache. Instead of multiple sets containing a single entry, fully associative caches have multiple cache entries all contained in a single set. Thus, the set number no longer provides any information and is not used. Instead, when a memory address is handled by the cache, every cache entry is checked for a matching tag. If found, the byte offset is used to output the correct data within the cache block.
Checking every cache entry makes fully associative cache consume far more power than direct-mapped cache. Finding a balance between power consumption and higher contention rates is done by using a set associative cache.

Figure 4. Fully Associative cache
Set Associative
A set associative cache offers the best of both worlds. It consists of multiple sets with multiple cache entries per set. How does it work? First, the set number allows the cache to jump to the appropriate set of entries. Next, each set of entries is searched for a matching tag. If found, the byte offset is used to output the requested data. This approach allows the cache to offer an optimized balance of power consumption and contention rate.
Figure 5 shows a 4-way set associative cache. It is called 4-way because each set can contain up to four cache entries. If each set could hold only two cache entries, it would be a 2-way. Thus, a direct-mapped cache is really just a 1-way set associative cache, while a fully-associative cache is a single set m-way set associative cache where m is the number of cache entries.

Figure 5. Set Associative cache
Management Heuristics
Once the logical organization of the cache is determined, a set of management heuristics needs to be decided. Management heuristics are simply a set of rules that determine how the cache performs its duties. These are typically implemented in a cache controller that sits above the cache and acts as an interface between it and the CPU. Cache management heuristics can be divided into two different categories: content management and consistency management.
Content Management
Content management heuristics are exactly what they sound like. They are a set of rules that determine when and what to cache. These heuristics identify important items that have been requested from memory and copy those items into the cache. Two examples of content heuristics are prefetching data items that are deemed important or soon to be used and replacement policies that decide what items get replaced when a cache set is full or near capacity.
Consistency Management
Consistency management heuristics are all about keeping the cache in sync with other memories. This can mean main memory, other cache levels within a hierarchy, or even the cache itself. For instance, a cache should never have multiple copies of the same data within its cache blocks. Furthermore, if a cache and main memory have different copies of what is supposed to be the same data, an application may receive an outdated or stale data item. This is especially possible in multi-core systems. Thus, consistency management heuristics might periodically update main memory with a newer version of cached data.
Review of the Basics of the CPU Hardware Cache
This article introduced some foundational principles of the CPU hardware cache. A CPU cache works on the principle of locality of reference, which is the tendency of processors to make predictable reads and writes to memory within a short period of time or at adjacent memory locations. Other design principles discussed were how to logically organize a cache and the rules that need to be defined to manage that cache. Caches can be found in virtually all CPUs, and cache design techniques have been extended into software caches and web-based caches for storing browser data or web documents. I hope that this article has helped you to better understand and appreciate this important technology.










Some please help me pick out the best product among those mentioned on the site.
https://11must.com/best-clamp-meters/