Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinMaking the Cloud More Powerful: Xilinx FPGAs and Adaptive Workload Acceleration
Historically, FPGAs have been challenging to work with. To combat that reputation, Xilinx developed programmable devices that simplify—and accelerate—the implementation of customized hardware development.
Historically, FPGAs have been challenging to work with. To combat that reputation, Xilinx developed programmable devices that simplify—and accelerate—the implementation of customized hardware development. Companies are using these devices in a variety of ways to accelerate compute-intensive tasks, including convolutions or matrix multiplications.
Imagine having the capability to improve people’s lives through access to supercomputing technology. Xilinx’s high-level, system-oriented workflow helps make that possible by simplifying the implementation of customized hardware acceleration. This ecosystem opens the doorway for applications designers to exploit the power of Xilinx programmable devices without the need for a large hardware and logic design overhead. This paradigm challenges the preconceived attitudes that integrating FPGA-level acceleration will necessitate the nightmares of yesterday’s FPGA development bottlenecks. It is now possible to efficiently integrate custom hardware acceleration—it’s a practical strategy that is already being used in products that cause disruptive, life-changing social transformations.
FPGAs have a deserved reputation for being difficult to work with. The same could be said for the early days of software design before the development of high-level design methodologies, comprehensive libraries, and highly integrated toolchains. Custom logic design lagged behind software development, as its hardware focus requires the added complexities of synthesis, fitting, and timing. Over time, the tools have caught up to and integrated with modern software development workflows, and comprehensive libraries of tried-and-tested IP have further simplified design.

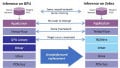
Figure 1. Reconfigurable acceleration is necessary for workloads moving between the Edge and the Cloud.
Now, FPGA-based acceleration can be practically considered as just another underlying technology at a software designer or system architect’s disposal. This capability is finding its way into many real-world applications as designers recognize and exploit the advantages that it offers. How much of an impact does this change in thinking have on everyday life? The best way to assess this is to first look at how FPGA design has progressed and then take a closer look at some use case examples, exploring how developers are integrating FPGA acceleration.
FPGA Design Progression
FPGA hardware designers are able to build custom hardware accelerators by interconnecting logic elements using low-level register transfer level (RTL) descriptions of the underlying circuit. In most cases, these hardware designs are implemented using schematic tools or compiled from structural and behavioral architectural descriptions of hardware languages like VHDL and Verilog. Design at this level requires expert knowledge of tools, languages, and synchronous design practices. Even then, simulation of the functionality with test benches, optimization for timing, resources, and power for the specific FPGA target, and integration of other IP can exponentiate the challenge.

Figure 2. Xilinx's development platform covers the hardware and software persona.
Over the years, Xilinx developed higher level tools to build IPs in C/C++ or in the MATLAB environment, where users can accelerate compute-intensive algorithms, such as video processing, with FPGAs in the loop. Today, using the Xilinx SDAccel environment, software developers can design custom hardware in a software programming language by using FPGA-accelerated library functions in their C/C++ or OpenCL (Open Computing Language) code. The functions themselves can be written in C/C++ or even RTL. RTL hardware functions can be packaged and then accessed as software “C-callable” functions. From the software design perspective, these are implemented in the same way as one wraps assembly routines using #pragmas and intrinsics.
Since OpenCL provides mechanisms for generic execution across heterogeneous platforms, such applications run on a CPU but are able to use whatever accelerator is available, whether FPGA, GPU, or DSP, without the system designer writing a single piece of FPGA code.
SDAccel for OpenCL
Underpinning Xilinx cloud-based computing hardware acceleration is Xilinx’s software-definable environment, SDAccel for OpenCL. With a GPU and CPU-like programming experience in a single software “cockpit”, the architecturally optimized compiler enables flexible, on-demand runtime configurability for solutions that exploit Xilinx FPGA partial reconfiguration technology.

Figure 3. Development stacks from Edge to Cloud.
This development stack includes RTL, C/C++, and OpenCL compilers, as well as a runtime software, drivers, and application libraries used to accelerate open software frameworks such as the ones used for machine learning, video transcoding, and big data analytics.
Being abstracted from the hardware acceleration platform and creating an architecture where an FPGA is purely an acceleration resource makes performance inherently scalable. Application designs utilizing this development stack, remove the dependency software traditionally had on the hardware platform, making the accelerator code both more easily reusable and futureproof, as it can target future FPGA resources without significant redesign.
Real-World Applications of FPGA Acceleration
FPGAs for workload acceleration have become easier for system designers and much more accessible to scientists or SaaS users without them even realizing they’re using an FPGA. For instance, if the application itself is a domain-specific development environment, data scientists can write algorithms and explore information spaces through FPGA acceleration.
Caffe and Google’s TensorFlow are examples of machine learning frameworks which utilize Xilinx FPGAs to significantly accelerate compute-intensive tasks, including convolutions or matrix multiplications. Other software frameworks that utilize FPGA acceleration include the likes of FFmpeg for video transcoding, Gatk for Genomics, and Storm for streaming analytics.

Figure 4. FPGA Cloud Acceleration impacts a variety of data-centric companies. The middle column indicates how much faster these programs are through FPGA acceleration.
Amazon Web Services
Amazon Web Services (AWS) is a secure cloud services platform that offers the capability to connect applications to computing, database, and other resource provision. Compute resources on the Amazon “Elastic Computing Cloud” (EC2) include Intel and AMD CPUs, Nvidia GPUs, and Xilinx FPGAs. EC2 enables powerful, scalable algorithms for accelerating “F1 Instances,” which are based on Virtex UltraScale+ FPGAs. Developers use this resource to implement algorithms like machine learning inference, video transcoding, big data analytics, or genome analysis, with orders of magnitude higher performance and lower cost than alternatives.
Edico Genome
These hardware accelerated functions are then packaged as software APIs, or made available in the AWS Marketplace as a pay-per-use software application. In turn, SaaS providers use these accelerated functions as part of their software offering. One such developer for genome analysis is Edico Genome. Genome sequencing solutions will then use Edico’s Cloud-based accelerator as part of their offering to hospitals around the world. Through this access, Xilinx FPGAs help save lives and improve outcomes of newborn infants by providing custom hardware workload over the Cloud.
Note: while this article was being written, Edico Genome got acquired by Illumina, Inc., a leader in genome sequencing.
Nimbix
Xilinx has also partnered with Nimbix, a leading provider of heterogeneous accelerator clouds, namely the Nimbix Cloud. Much like AWS, OpenCL examples can be downloaded from GitHub, allowing developers to immediately compile them to get familiar with the development flow. Applications can be written, while executables and accelerator hardware modules can be compiled and finally uploaded to FPGA cluster where data processes.
A clear example of this data process acceleration is video codec acceleration, as the HEVC decoder is available for designers on the Nimbix-powered cloud using Xilinx SDAccel environment. Hardware accelerated 4k video codecs, like the RealityCodec from NGCodec, are also available on Amazon’s AWS EC2 F1 instance. The codec utilizes multiple Xilinx UltraScale+ FPGAs to deliver ultra-low, subframe latency intended to support cloud-based virtual and augmented reality applications.
Baidu’s XPU
There is no “killer app” when it comes to data center workloads. This means hardware adaptability is paramount. FPGAs provide the flexibility needed for data centers to adapt to custom accelerators as things change. For this reason, companies like Baidu are releasing new flexible combined FPGA, CPU, and GPU architectures like the XPU. The XPU is a cloud-based 256-core hardware accelerator based upon the Kintex UltraScale FPGAs, designed specifically for data center acceleration services. The design generically supports massive matrix array maths with extremely high bandwidth and low latency, with all 600MHz cores clustered around a single shared memory structure and external DDR4 memory banks.
This is intended to be used in Baidu’s hybrid cloud platform, where they offer infrastructure supporting AI, machine learning, and large data analytics and cloud computing services. Microsoft Azure is also offering an FPGA-based configurable cloud with their Azure Server to support the explosion in data volume on the web, enable users to gain insight on that information, and to support the massive overheads of their own cloud-based services.
High Performance and Acceleration
Xilinx’s cloud-based computing acceleration is having a disruptive impact on both hardware development and computing business models. High-performance computing does not need to be done in-situ on cloud-connected smart devices; instead, data can be sent to cloud-based hardware acceleration services for analysis.
Imagine, as an example, a fictional “Star Trek” Tricorder, the handheld medical analysis device Dr. McCoy used to diagnose patients. Instead of a massively expensive supercomputer with the power drain of a small hydroelectric dam, the device only requires sensors, a network connection, a human-machine interface, and a subscription to a workload acceleration service to view results. Scalability means the Federation can pay for Dr. McCoy to get results in 30 seconds with the “gold” service, instead of two minutes on the normal subscription. Data analysis can also be decentralized under this model. Acceleration doesn’t have to occur at a central location; rather, it can be spread amongst different physical locations, perhaps capitalizing on reduced cooling costs of some of these locations.
Although FPGAs are now part of the cloud, it’s important not to lose sight of their special characteristics to understand where and when they make for good acceleration. For example, FPGAs work at the gate level, meaning that bus widths, coefficient precision, and the degree of sequential to concurrent processing are all up for grabs. CPUs and GPUs do not offer this flexibility. This enables applications like neural networks, filter banks, and matrix operations to have optimum precision at each stage. So, a process that only requires 14 bits gets exactly 14 bits’ worth of precision in the multiplications, rather than 32 or 64 bits.
Memory accesses can be packed by a custom hardware interface, improving memory access power efficiency and database size—for example, packing 10-bit pixels into an external video frame buffer where the memory is 32-bits wide. Other benefits include the ability to stream data pipes directly from one accelerator to the next through smaller internal memory FIFO buffers and avoiding power hungry, performance-sapping external bus accesses.
The Future of Adaptive Workload Acceleration
What is the future of FPGA acceleration? Xilinx is revolutionizing the underlying technology of FPGAs, optimizing their devices to make them better for the implementation of neural networks with the Adaptive Compute Acceleration Platform (ACAP). An ACAP has all the normal distributed memory, DSP blocks, and logic of an FPGA with a multicore SoC, all connected by a network on chip (NoC) to one or more of hardware adaptable compute engines.
The first in the product family, Everest (available for customers in 2019), developed on a TSMC 7nm process technology, will empower endpoint, edge, and cloud applications. This will enable applications to process workloads like genomic sequencing using neural networks working at over 20 times the speed of current FPGA acceleration, leading to massive technological advances in areas like genomics, machine vision, video transcoding, data analysis, and communications, because the platform will deliver unparalleled performance per watt efficiencies. The technology is ideally suited for 5G applications and will accelerate future cloud services platforms.
Software and system developers all want results, and the design process has to progress far too quickly to allow time for designers to dally in low-level efforts that will surely become a series of project-delaying techno dramas. Researchers and scientists need their innovative new solutions to go blindingly fast. Xilinx’s complete hardware acceleration ecosystem makes FPGA-level performance accessible in ways people only dreamed of a few years ago. Now that this technology is mainstream, FPGA acceleration should be considered for any cloud-based application. Xilinx FPGAs now carry all the advantages of high performance, low power consumption, and highly integrated designs delivered directly into a developer’s hands.