Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinEdge AI Development Is a Lifecycle Problem
Edge AI success is limited by memory and power. Fragmented tools cause failures. Learn how a cohesive, full-lifecycle approach unifying design and deployment is essential for scalable systems.
Edge AI developers face a tight set of constraints. Limited memory, strict power budgets, and constrained compute mean that success depends on more than model accuracy. When margins for error are this small, every stage of the development lifecycle matters.
Successful deployments depend on a cohesive, full-lifecycle approach to edge AI. This requires tools and workflows that connect each stage of development, from model design through deployment.
A growing number of platforms are starting to address this need by combining hardware and software into more unified development environments.
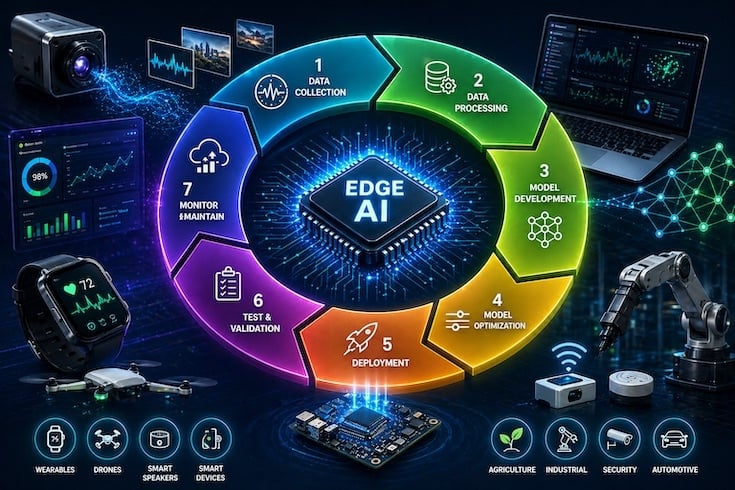
The lifecycle of Edge AI system development. Image used courtesy of Ceva.
Design and Training Realities
For AI engineers, edge development begins in the design and training phase, where embedded constraints reshape standard workflows.
Unlike server environments, MCU-based IoT devices often have only a few megabytes of flash and SRAM and operate within power budgets below 10 milliwatts. Models cannot simply be scaled down from the cloud. They must be architected specifically for the target hardware, with careful control over memory footprint and data reuse.
Data introduces another layer of complexity. Edge applications rely on local sensor inputs that are often limited, noisy, or unlabeled. Engineers must apply augmentation and domain-specific preprocessing that remains robust after quantization and on-device execution.
At the same time, inference rarely operates in isolation. It sits within a real-time pipeline that includes DSP workloads and control loops, all competing for the same compute and memory resources. Without accounting for these interactions early, teams risk developing models that perform well in theory but fail in deployment.
Friction in Cross-Framework Deployment
The design and training phase is further complicated by fragmentation across the AI workflow.
Models are typically trained in frameworks such as PyTorch, while deployment depends on runtimes like LiteRT Micro or uTVM. This mismatch creates friction through operator incompatibilities, differences in padding semantics, and inconsistent data types. These issues often surface as subtle bugs that are difficult to isolate.
Discrepancies between formats such as ONNX and TFLite add another layer of risk. While conversion tools continue to improve, incompatible graph transformations and representation differences remain common.
In practice, even minor mismatches in tensor shape or quantization scaling can cause entire pipelines to fail. Without unified import pipelines and cycle-accurate simulation, engineering teams can spend weeks tracing issues back to earlier stages of development.
The Complexity of Optimization
Optimization is often where edge AI projects succeed or fail.
Engineering teams must balance competing requirements, including model size, inference latency, active power, and memory bandwidth. Improvements in one area frequently create regressions in another. For example, increasing accuracy may drive higher memory traffic or energy consumption.
Quantization adds further complexity. INT8 quantization is widely used in edge deployments, but real-world sensor noise can amplify quantization errors and degrade model accuracy.

Optimization is a stage where edge AI projects can succeed or fail. Image used courtesy of Adobe Stock (licensed).
At the same time, model architectures and operators continue to evolve faster than embedded runtimes and toolchains. Without flexible execution architectures and extensible software stacks, teams are forced to modify models or offload unsupported operations to general-purpose processors, which reduces efficiency and increases power consumption.
Integration and Validation Challenges
Even well-designed and optimized models can fail during integration. Edge systems introduce conditions that are difficult to replicate in simulation, including real-time control workloads, shared resource contention, and multiple power domains. These factors often expose issues late in development. Debug visibility is a major limitation at this stage. Identifying whether failures originate in the DSP pipeline, neural network kernels, or memory scheduling requires integrated profiling and system-level insight.
Consistency is another challenge. The gap between Python-based development and C/C++ deployment can create reproducibility issues when toolchains are not aligned. Reliable validation requires hardware-accurate simulation and test pipelines that reflect real-world operating conditions.
Unlocking the Full Lifecycle
Addressing these challenges requires moving away from fragmented workflows toward a more unified, software-centric approach.
When training, quantization, optimization, and deployment are handled in separate tools, engineers lose visibility into how early decisions affect downstream performance. A unified approach maintains a consistent model representation across the lifecycle and allows teams to evaluate system behavior under realistic constraints.
Several vendors are developing integrated platforms to support this shift. At the hardware level, modern edge NPUs are designed to handle both neural network execution and control tasks, with features such as efficient data movement and memory optimization to meet strict power and resource limits.
These capabilities are paired with software environments that connect model optimization, compilation, simulation, profiling, and deployment into a single workflow. Maintaining consistency across these stages helps preserve model behavior and system assumptions as designs move into production.
Lifecycle-Based Approach is Essential
As embedded AI workloads grow in complexity, a lifecycle-based approach becomes essential.
By aligning hardware and software development more closely, the industry is beginning to treat edge AI as a continuous system rather than a sequence of disconnected steps. This shift reduces integration risk and improves the likelihood of successful deployment at scale.