 Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinCan We Give AI the Ability to Form Memories? The Basics of Hyperdimensional Computing
Is hyperdimensional computing the future of AI? Learn about a theory that could revolutionize machine vision.
Is hyperdimensional computing the future of AI? Learn about a theory that could revolutionize machine vision.
It is mostly described as a way to enable AI systems to retain memory, instead of computing everything it senses. This takes AI a step closer (albeit only slight and theoretical step) towards more human-like cognition.
Currently, when an AI system sees a chair, for example, it has to detect it and compute the characteristics to decide if it is a chair. When a human looks at a chair, on the other hand, it has seen a chair before and can infer from memory this object is also a chair. This is sort of what hyperdimensional computing is expected to be able to do for AI. More specifically, it’s providing some form of "memory" to a system so that similar things can be easily identified together.
Hyperdimensional computing theory is not new—in fact, the first publication on the topic was released in 2009, roughly a decade ago. It’s an interesting concept, however, and it’s worth knowing how it works under the hood at a very high level, what makes it different from traditional computing, and why it’s suddenly in the spotlight.
What Are Hyperdimensional Vectors?
The prefix "hyper" might make this concept sound like some science fiction invention, but really what the term "hyperdimensional vectors" is referring to is the size of the vectors typically used in computing processes, and the possible information they can contain.
In a traditional computer, there are vectors that represent the address of an instruction and then the vector for the instruction, itself. The size of such vectors might be something like 32-bits and the position of each bit will confer some very specific meaning. For example, if an operation portion of a vector is the first three bits, then maybe 000 means add, 001 means subtract, the next few bits might be the value the operation is to be applied to, and so on.
This method of computing is binary and very reliant on information being represented correctly and in the right places to achieve the right output.
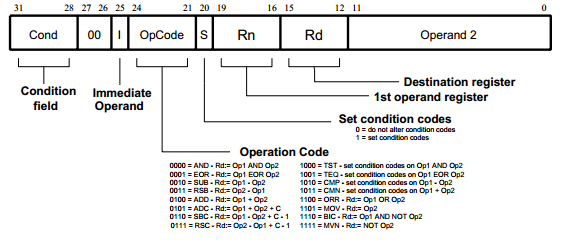
An example of an Arm instruction. If the instruction set was 10,000 bits instead of 32, then statistical processing could be used to interpret it. Image courtesy of Arm.
Hyperdimensional vectors can be much larger, perhaps even 10,000 bits long.
This many bits, however, do not give better resolution to the type of information it can represent; in fact, it would be difficult to give exact meaning to a vector of 10,000 bits the way we do in traditional computing. Instead, meaning can be inferred from other properties, such as statistical distribution of values, similarity in patterns, or hamming distances.
As such, the meaning of the overall vector is no longer tied exclusively to the position of each bit value, but spread across it overall, and abstracted by some other means to decide what the vector is actually representing.
This is all very abstract, but a good example provided by the researchers provide a four-bit example.
Let's say that we have four vectors, A, B, C, and D, where:
A: 0000
B: 0011
C: 0001
D: 0010
We can see that C is more similar to A and B than it is to D. That is, C has three common bits with A and it has one common bit with B—but it has no common bits with D.
In traditional computing, we would probably say these four vectors have nothing in common when it comes to what they represent. The fact that similarity is now a property we can consider among these vectors adds a layer of information that can be used to infer its meaning. This adds a "dimension"—hence, the term hyperdimensional.
So, a hyperdimensional vector is just a really large vector that can be interpreted by doing more than reading the value of each bit at every position.
Memory Robustness and the Likeness to Human Cognition
One thing we humans are good at is being able to recognize patterns, and using those patterns to tell us information about other similar things. Going back to the chair example from earlier, humans generally understand that just because a chair is missing one leg, that doesn’t mean it’s suddenly not a chair. An AI at this stage in their evolution, however, may look at a broken chair and decide it is a completely new object that must be identified and classified.
Hyperdimensional vectors give us the same margin for error: maybe some of the bits are different, but if two vectors are similar enough, the abstracted patterns and values (such as the statistical distribution of bits) won’t be significantly different. This gives us excellent robustness against noise or mistakes.
Going into the potential architecture of such a system using hyperdimensional vectors, we can think about how a computer might read a vector and then try to retrieve a similar vector to decide what it is. If the vector, called X, is used as the address of itself, then when X is read we can identify X right away.
If some slight variation of X is read, let’s call it X’, it’s not the same as X, but the abstracted interpretation of it (let’s say by statistical similarity) will bring us to a region of memory very close to X. In traditional computing, 0000 and 1000 are completely different, so you would not converge on the address if one bit is different, or be anywhere close.
Following this logic, a chair and a stool will have different vector representations. They are not exactly the same object. A chair, by definition, has a back. Maybe it’s a lower back or a higher back, depending on the sample. It could be a different color. A stool, by comparison, doesn’t have a back and is therefore a different shape and possibly taller. Even so, human brains know that there's a flat part you can sit on, especially as stools are often placed by some type of table. We can infer that, just like a chair, we can sit on a stool.
In hyperdimensional computing, a chair and stool are stored in the same region of memory close to couches and other pieces of furniture you sit on. We also recognize that a chair has no relation to a bird; and, in our theoretical hyperdimensional computer's memory, a reference to a bird would not bring us to the same memory region either.
A more complex example is a chair with a broken leg.

Readers probably know this is obviously a chair; current object recognition software might have a harder time discriminating this. Image courtesy of Nonteek.
In traditional object recognition, this is a difficult task. With hyperdimensional computing, recognizing certain features will generate a vector that is similar enough to a chair that when it is abstracted and processed, you—in theory—end up in the same "memory region" as a chair that is unbroken.
Recent Applications for Hyperdimensional Computing
As I mentioned earlier, hyperdimensional computing is getting some extra attention in the press. This is partly because, recently, researchers from the University of Maryland published a paper called "Learning sensorimotor control with neuromorphic sensors: Toward hyperdimensional active perception". The paper was published in the journal Science Robotics and discusses the use of hyperdimensional binary vectors (or HBVs) for processing sensory data in robotics.
The paper presents a possible leap forward in what's referred to as "sensorimotor representation"—creating responses based on sensory input. In practice, this could translate to an AI-controlled robot that is capable of learning something akin to muscle memory. As the University of Maryland article on the subject explains, "...the paper marks the first time that perception and action have been integrated."
Even based on a single application such as this, it's clear the future uses of hyperdimensional computing are vast in scope.
I hope you can come away from this article with the general idea of hyperdimensional computing at a very high level. The field of AI and computer cognition requires expertise across several domains, but demystifying some of the terminology and concepts that are being used can definitely help make potential advancements in the field more digestible.
Do you have such expertise in computer cognition? If so, please share some of your perspective on this topic in the comments below.
Featured image used courtesy of PixaBay.
Related Content












Thank you for this excellent brief introduction to hyperdimensional computing. As you outline, hypervectors are extremely robust against noise (as is the central nervous system) and this is one of the reasons hyperdimensional computing (HDC) is very interesting for energy-efficient implementation (which is often associated with relatively higher levels of noise). In our own work we have used HDC for processing electrical brain signals (iEEG), see for example: https://www.researchgate.net/project/Hyperdimensional-computing-for-iEEG-analysis
For a didactically outstanding introduction I highly recommend the beautifully written review paper by Pentti Kanerva: http://www.rctn.org/vs265/kanerva09-hyperdimensional.pdf
Looking forward to many more applications of hyperdimensional computing in the (near) future.