Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinNvidia Issues Major Update of CUDA Toolkit to Accelerate CPUs and GPUs
CUDA Version 13 features new CPU resources, unified Arm platforms, and additional operating systems supported.
Nvidia has released the latest update to its CUDA Toolkit, with version 13 introducing significant performance updates.

CUDA Toolkit version 13 now supports the latest Blackwell GPU family.
The upgraded toolkit comes with programmer ease-of-use enhancements, greater compatibility, and language acceleration. Version 13 also presents tile-based programming to the Nvidia world for the first time, further reducing programmer workload.
What Is CUDA?
Graphics processing units (GPUs) are optimized for highly parallel operations with many small processing cores. On their own, they are difficult to program for non-graphics operations. CUDA is Nvidia's development environment that enables high-performance computing applications other than graphics rendering. The CUDA platform is a layer that sits between the GPU and general-purpose applications programs that can benefit from parallel operations. CUDA also contains an extensive set of libraries, compiler directives, and language adaptations.
AI large language model development and usage, scientific analysis, and cryptography are some of the complex applications that benefit from massive parallel processing available with GPU and multiple GPU systems. CUDA is designed to make these use cases available to a broad set of application developers.
Key Updates to Version 13
CUDA 13 adds support for Nvidia’s newest Blackwell GPUs, the Jetson Thor advanced AI and robotics GPU, and DGX Spark “desktop supercomputer.” It supports Nvidia's GPUs up through current architectures (dropping pre-7.5). It also updated vector types with 32-byte alignment for increased performance on Blackwell.
The toolkit unifies the developer experience on Arm platforms, providing a single toolchain that covers both server and embedded applications. It includes updated OS and platform support, including Red Hat Enterprise Linux 10, Debian 12.10, Fedors 42, and Rocky Linux 10.0 and 9.6. It features updates to Nvidia Nsight Developer Tools to improve dependency checking and CUDA math libraries, including cuBLAS, cuSPARSE, cuSOLVER, and cuFFT.
NVCC Compiler now supports GCC 15 and Clang 20, as well as new language features to improve application binary interface (ABI) integration. Users will discover an accelerated Python core and developer-friendly packaging. The Wheel package and CUDA Core Compute Library (CCCL) have also optimized library organization.
Unifying Server and Embedded Development in One Toolchain
Prior to version 13, CUDA could almost be thought of as two separate products. Developers needed one toolchain installation for server-class projects and a completely separate one for embedded-class projects. The syntax and operation were very similar between the two, but the libraries, headers, and other development components were different for server and embedded targets.
Version 13 eliminates that limitation. Now one toolchain can be used for both targets. The resulting binary is optimized for whatever GPU the developer is using without the need to switch toolchains based on the deployment scenario.
The new version also consolidates the Arm code that goes along with GPU deployments. The Arm binary is compatible across all Arm targets (with Orin sm_87 being the single exception) and simulation platforms. Previous versions required different toolchains for simulation and deployment.
Tile-Based Parallel Programming
Tile, or array-based programming, enables commands to be enacted on all data points in an array or matrix simultaneously. Parallel programming often requires the same operations to be performed on multiple data blocks at the same time. Tile programming automatically takes care of the parallelism for the programmer. A single function is coded, and the underlying intelligence layer takes care of all of the low-level detail to make the operation parallel.
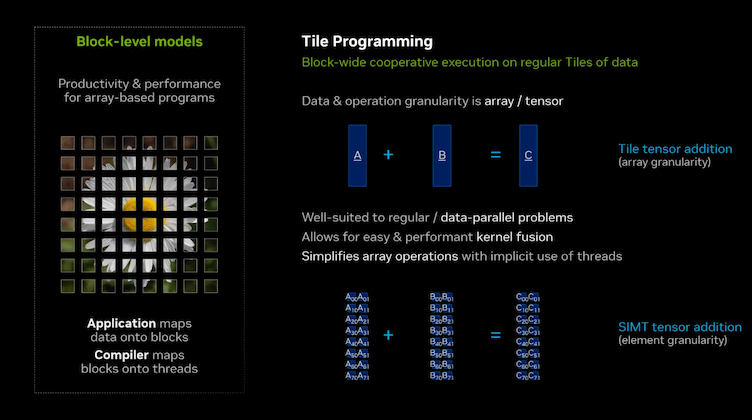
Comparing block-level vs. tile-based programming.
The compiler and runtime system are responsible for distributing the load around threads and cores. The abstraction layer maximizes performance with a much lower coding burden.
Available Now
Version 13 of the Nvidia CUDA toolkit is now available for download at no charge. Nvidia offers multiple distribution support for Linux x86_64 and arm64-sbsa, and x86_64 support for Windows 10, 11, Server 2022, and Server 2025.
All images used courtesy of Nvidia.
Related Content