Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinConsiderations for Choosing Edge ML Application Hardware
As edge machine learning (ML) applications keep growing, EEs need to understand ML at the edge, especially concerning processing and processing hardware.
With the increased proliferation of edge machine learning technology, it is necessary for engineers to understand what ML at the edge is and how different types of hardware are suitable for its various applications. This is, first and foremost, a question of definitions. An edge node is not simply a device that relies on cloud services, and an edge ML product/application cannot be properly specified without a reasonably detailed understanding of what, exactly, ML at the edge is (and what its benefits and drawbacks are).
Engineers working with ML at the edge must account for, at the beginning of their design process, the relevant application features, and product dimensions. This is not a minor consideration. Projects that don’t account for these fundamental design considerations may experience extra design cycles and inefficiencies that cascade throughout a finished product’s lifetime.
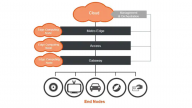
Figure 1 shows a high-level overview of edge devices and applications.

Figure 1. An overview of the edge and edge devices. Image used courtesy of NXP
To tackle this fundamental design problem, this article first defines ML at the edge and explores what processing devices are suitable for this domain. It then examines the question of processing power for these devices, and it finishes with an example ML application that illustrates how designers can begin to account for some of the considerations discussed throughout this article.
Benefits and Drawbacks to Find a Suitable ML Edge Device
The difference between an edge node (Figure 2) and a device that solely relies on cloud services to do the computation is the processing done by the edge device. If that processing step includes using ML algorithms, the device can be classified as an ML edge device.

Figure 2. Examples of edge computing and end nodes. Image used courtesy of NXP
The processing step can be as simple as computing a moving average or discarding invalid sensor readings. However, more involved applications might perform ML-based tasks like keyword detection or speech-to-text conversion before uploading data to the cloud. Therefore, edge devices can do all their processing locally or use a hybrid approach with local preprocessing and further processing and data storage in the cloud.
The benefits of using ML at the edge over a purely cloud-based approach include decreased latency and increased security. ML at the edge allows for real-time inference, and data that never gets uploaded to the cloud is more difficult to compromise.
However, edge devices typically offer lower processing power compared to the cloud. Therefore, they can usually not act on the same models that engineers could deploy in a cloud-based application. Engineers must carefully choose the algorithms and techniques they use at the edge to ensure that the application reaches the desired performance level.
Depending on the application, some edge nodes must also store data they collect and process before uploading it to the cloud. Storage space is typically plentiful in the cloud. However, at the edge, one must carefully consider how they add external storage to an edge node and what type of storage media they attach to the devices. Thus, they should investigate edge processors with diverse connectivity options to ensure they have more options when choosing storage media for their applications.
Engineers must also ensure that data stored by an edge node is secure and protected against unauthorized access and tampering. Features such as hardware encryption/decryption support can help protect sensitive customer and operational data at the edge.
Processing Unit Types for Machine Learning
Microprocessors (MPUs) and microcontrollers (MCUs) have seen considerable advances in overall processing performance and capabilities in recent years. Further, these devices experienced a significant reduction in cost and power consumption. Many of these devices include multiple dedicated processing cores for performing various specific tasks in parallel. In addition, microcontrollers aimed at the IoT and edge computing market typically also incorporate a plethora of state-of-the-art connectivity and security options.
Due to the significant increase in processing power at the edge, edge devices can perform more and more ML tasks previously conducted in the cloud. ML inference commonly happens at the edge, while the cloud offers increased analytics capabilities to enhance the ML edge application.
While microprocessors rely on external support devices connected to the processor via a system bus to perform various tasks, MPUs integrate all necessary features on a single system-on-a-chip (SoC). Such an MPU can contain multiple dedicated processing units, flash memory, RAM and ROM, and periphery controllers, for example, an Ethernet interface. An MPU can perform edge ML calculations using internal processing units such as a:
- Central processing unit (CPU)
- Graphics processing unit (GPU)
- Digital signal processor (DSP)
- Neural processing unit (NPU)
Engineers can use these processing units independently; however, some applications may require multiple processors to work in unison.
CPUs and MCUs
Most CPUs and MCUs contain multiple processing cores that allow them to perform more computations per second than would be possible with a single-core architecture. They are optimized for quickly executing chains of complex commands, which can be difficult for more demanding ML applications.
GPUs
Dedicated GPUs excel in executing many simple calculations such as matrix-matrix multiplication in parallel. One problem when using them for ML applications can be the availability of memory. While CPUs can often access large amounts of RAM in the system, GPUs commonly use their built-in video memory due to faster access and higher data throughput.
NPUs
Engineers can employ an NPU, sometimes called NNP or TPU by some manufacturers, in their ML application design. These specialized circuits implement control and arithmetic logic blocks necessary for executing ML algorithms. NPUs accelerate ML tasks and allow engineers to implement more advanced use cases that would not be possible with hardware such as common CPUs or GPUs.
Processing Power as a Key Consideration for ML Applications
From a high-level perspective, ML can be split into three common types of applications. The three disciplines are:
- Vision
- Audio
- Time-series
As Figure 3 illustrates, processing hardware such as general-purpose CPUs and MCUs are suitable for some of the simpler use cases (e.g., still image recognition and detecting anomalies in sensor data). However, with increasing complexity, more input sources, and the need for faster inference results, engineers will have to investigate more specialized computing hardware such as GPUs and dedicated neural processing units.

Figure 3: Outlines the processing power needed for running various ML applications. Image used courtesy of NXP
Naturally, embedded processing devices, such as MPUs, cannot offer a large number of processing cores and memory required for some more complex ML applications due to their small physical size. In addition, customers expect all necessary features combined in a single package to reduce their BOM for an embedded design. This requirement further reduces the available space for additional processing cores. In addition, most IoT applications need to be relatively small, efficient, and cost-effective.
In most cases, the limiting factor for edge ML applications will most likely be the model size and memory requirements for specific algorithms, as the amount of memory available to a cost-effective local processor is typically small. There is a break-even point for every application at which it does not make much sense to add additional processing power at the edge. At that point, the cost of increasing the processing power at the edge outweighs the benefits.
Therefore, adding computational power at the edge is only viable until the application reaches a certain complexity limit. Beyond that, engineers should look into ways the advanced data analytics capabilities of the cloud could potentially augment the processing power at the edge.
Choosing a Suitable Edge Processor: An Example ML Application
Many use cases allow engineers to enhance existing applications by adding ML edge capabilities. The possible applications range from the smart-home sector to Industrial IoT (IIoT) and industry 4.0 to connected city infrastructure and automotive applications.
As an example, consider someone who is installing an automated vision-based road toll payment and traffic violation detection system on a highway. This use case has many potential points for combining cloud technology with ML at the edge.
Such a system must reliably detect each vehicle approaching a certain point, such as an entry or exit ramp. In this example, an edge device monitors each vehicle approaching the ramp. The system must then correctly classify each vehicle on the ramp (e.g., car, semi-truck, bus, motorcycle), as different road tax regulations may apply to various types of vehicles. Drivers could have their license plates registered with the local authority when paying the toll for their vehicle. Then, the edge device must detect the license plate number of each vehicle that passes the checkpoint. The system could then store the collected information locally and later request data from a database server in the cloud to check whether the detected vehicles are allowed to use the road. For privacy reasons, the system should not upload the license plates of all vehicles that pass by the checkpoint. Instead, it only sends the ones that commit a violation to the cloud for further processing, for example, sending out a ticket to the vehicle owner.
Possible future adaptations of this system could also detect potential problems, for example, a traffic jam on an exit ramp, and warn upcoming drivers by turning on overhead signs. With the rising number of connected vehicles on public roads, it's also possible to make these edge nodes communicate with cars to transmit warnings or other messages.
In this example, multiple data feeds need to be analyzed and appropriately handled in real time by edge processing. The system must monitor and classify vehicles in the video stream as they zip past the camera, and the video needs to have a sufficiently high resolution and framerate. According to Figure 3, each such application requires an ML processor capable of handling around two TOPS. In addition, the edge node should be able to securely store and upload sensitive private information to a cloud server.
In conclusion, a properly specified device for this ML at the edge application should deliver the following features:
- A GPU or NPU accelerator for real-time image feature detection
- An efficient main core for running the application logic
- An interface for communicating with external high-resolution cameras
- Connectivity options for interfacing external industrial-grade equipment, for example, overhead signs and warning lights
- Ethernet/Wireless capabilities for establishing a connection to the cloud
- Security features that prevent unauthorized tampering
- Reliability features such as ECC
These functionalities (and more) are seen in NXP’s i.MX 8M Plus and Figure 4 below.

Figure 4: This block diagram summarizes the most important features and functional blocks of the i.MX 8M Plus. Image used courtesy of NXP
NXP’s i.MX 8M Plus: Enabling Machine Learning at the Edge
A hypothetical, simple automatic license plate detection algorithm could contain four main steps. These steps are image acquisition and pre-processing, license plate extraction, segmentation, and character recognition. A cost-effective HD camera monitors the entrance of a highway ramp. As the camera is a cost-effective unit, it outputs an RGB Bayer pattern without performing any pre-processing.
The NXP i.MX 8M Plus applications processor contains a dual-camera ISP that supports simple CMOS sensors and cameras performing more elaborate pre-processing. An additional built-in dewarp engine provides performant dewarp processing for correcting distortions introduced by fisheye and wide-angle camera lenses. Even though the built-in ISP of the i.MX 8M can handle HD video streams of up to 60 FPS, this application will only capture and process about thirty frames per second. The reduced frame rate should still create a satisfactory result, and the reduced computational demand and reduced data throughput will further boost the efficiency of each edge node.
Once the ISP finishes processing the image, the on-chip GPU of the i.MX 8M Plus can perform further image processing and manipulation steps, such as converting the color information of the captured camera image to a grayscale image before subsequently generating a binary black and white image. Lastly, the GPU can further prepare the image by creating smaller copies and applying filters that blend in imperfections, for example, ones caused by dirt or screws in the license plate.
The application processor then performs feature detection on the complete pre-processed input image to find the license plate in the image. Here, engineers could choose from various features they want the system to detect. Prominent features could be the background and font color of license plates, their shape, or other characteristics, for example, a country or state name. However, these depend on the location this system will operate in.
Either way, several methods exist to detect features in an image, for example, a histogram of oriented gradients (HOG), and the applications processor’s ARM Cortex-A53 main CPU can perform this step. Once the main CPU verifies that a license plate is present in the image, the application processor’s 2.3 TOPS NPU can utilize a DNN to perform character and additional feature recognition. The output could contain information such as the country, state, and license plate number.
The system can then store the data for later processing. Once it detects a violation, the device can encrypt the extracted information and upload it to a cloud server for further processing. The two Gigabit Ethernet interfaces (one of which includes TSN support) of the NXP i.MX 8M allows the edge node to upload large amounts of data to the cloud for further processing. The device’s enhanced on-chip security features ensure the confidentiality and integrity of sensitive user information.
Reliability and security are two more aspects that are important to consider in industrial applications. The i.MX 8M Plus offers inline error-correcting codes in the DDR RAM interface to ensure high reliability and support of safety integrity level (SIL) certification at the system level. Security features such as secure boot, encrypted boot, a hardware firewall, and a run-time integrity checker (RTIC) help prevent various attacks that could compromise the security of an embedded system, including hardware reverse engineering, malware insertion, modifying/replacing the device image, and version rollback attacks.
Summarizing ML Edge Processing Considerations
Just like with any other software project, understanding the requirements of an ML-based application at the edge is the key to a successful project that doesn't go beyond the scope. Once engineers identify and understand a project's requirements, they can investigate suitable hardware.
With the advance of increased processing power and more capable devices at the edge, more and more ML-based and analytics tasks moved away from the cloud. However, computing at the edge is not a replacement for the cloud. Instead, edge and cloud computing complement each other while simultaneously decreasing latency and increasing security and reliability.
Modern edge processors contain multiple dedicated processing cores precisely trimmed and optimized for specific tasks. Each type of processor has benefits and drawbacks when used for ML applications. While engineers can use them separately, these dedicated processing devices unfold their true potential when used in unison when implementing complex ML applications at the edge.
Apart from the sheer processing power, one must always consider the environment in which one wants to deploy the ML edge nodes. Some use cases, such as vision-based ML applications, might call for different hardware than audio-based applications, so it’s important to carefully evaluate the interfacing options of the investigated processing devices. Additional co-processors might help reduce the load on the main CPU of the chosen device, and engineers should also identify and consider safety-relevant aspects of each ML project at the edge.
Related Content