Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinUnderstanding ASCII in Embedded Firmware Development
This article, which serves as preparation for a discussion of C-language strings, introduces the concept of ASCII characters and explains two benefits of ASCII-based coding techniques.
This article, which serves as preparation for a discussion of C-language strings, introduces the concept of ASCII characters and explains two benefits of ASCII-based coding techniques.
Supporting Information
A microprocessor is a complex collection of circuits that manipulate logic-high voltages and logic-low voltages. For the sake of convenience we refer to these voltages as ones and zeros, and we design processors such that these ones and zeros can be manipulated simultaneously and treated as binary numbers.
Most people I know would lose their minds or fall asleep if they were forced to watch the endless flow of binary numbers into and out of a microprocessor. Computational technology has transformed human existence because these binary numbers can be used to represent things that people actually care about—music, photographs, or, in the case of ASCII, letters and digits.
Understanding ASCII
ASCII stands for American Standard Code for Information Interchange. In this code, one binary number signifies exactly one character, where “character” refers to an uppercase letter, a lowercase letter, a digit, a punctuation mark, or various other things that you can find on a keyboard. The following table gives you the “translation” between numbers (here written in decimal notation instead of binary) and the ASCII characters corresponding to the uppercase and lowercase English alphabet.

It is essential to understand that your microcontroller knows nothing about English letters, or punctuation marks, or digits. Your microcontroller is a very small binary-number-crunching machine, and any characters that are present in your firmware are simply your interpretation of binary numbers. Serious confusion can result from the mistaken impression that your variables or array elements actually contain ASCII characters in some form or another. Firmware development becomes more clear, more streamlined, and more flexible when you realize that characters are in reality binary numbers and can be stored, transferred, and manipulated as binary numbers—they do not become ASCII characters until you are ready to interpret them as ASCII characters.
ASCII Pros and Cons
I am a proponent of ASCII. There are many embedded applications that can benefit from use of ASCII characters, and I think that it’s a good idea to get into the habit of recognizing situations in which you can incorporate ASCII characters into your code.
A Widely Used Standard
An undeniable benefit of ASCII is the standardization. Integrated development environments, terminal programs, and computational software packages understand ASCII, and consequently ASCII characters are a convenient and effective way to transfer and display information.

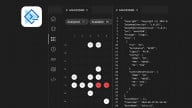
In this example, my colleague Mark Hughes is using an application called PuTTY to display an ASCII-based binary representation of precision inclinometer data.
Reliable Data Transfer
A more subtle, but perhaps equally important, benefit is the fact that ASCII provides a means of representing information using a restricted set of binary numbers. Any numerical value can be represented by a sequence of the ASCII digits 0 to 9 (along with the ASCII decimal point if needed). These ASCII characters correspond to a very small subset of the 256 values offered by an 8-bit binary number. But why does this matter?
Imagine that you have an application in which a microcontroller must transfer unpredictable and highly variable 8-bit sensor measurements to a PC. If you transfer the data as ordinary binary numbers, an individual byte can contain any number from 0 to 255. This leaves you with no convenient, straightforward way to organize data or incorporate commands into the data stream, because all possible binary numbers are needed just to transfer the raw measurements. The PC cannot distinguish between numerical measurement data and other types of information.
If you transfer the measurement data using ASCII characters instead of ordinary binary numbers, the benefits of the restricted set come into play. You need only ten binary values (corresponding to ASCII digits 0 to 9) for representing the numerical data, and various other binary values can be reserved for special functionality because these will never appear in the measurement data. (If you want to read about a higher-performance, but more complicated, approach to organizing digital data, take a look at my article on packet-based communication.)

Here, ASCII digits are being used to transfer temperature readings. The end of each reading is identified by a carriage return (abbreviated CR); the binary value corresponding to CR will never appear in the measurement data.
Reduced Efficiency
The price that you pay for standardization and improved data transfer is a less efficient use of memory, processor bandwidth, and communication bandwidth. ASCII is a byte-based system. Each character requires eight bits—even, for example, the digit ‘1’, which under normal binary circumstances can be represented by a 1-bit number instead of an 8-bit number.
In my experience this is rarely a serious problem; modern microcontrollers have processing power and memory resources that far exceed the requirements of many applications. However, if you really need to maximize throughput or minimize memory usage, you may need to forgo the convenience of ASCII.
From ASCII to Strings
As mentioned in the introduction, this article is not only an overview of ASCII but also an introduction to the way in which a character-based representation is handled in the C programming language. We refer to this type of representation as a string—it is a sequence, or “string,” of ASCII characters. We’ll take a closer look at strings in the next article.