 Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinHow to Perform Classification Using a Neural Network: What Is the Perceptron?
This article explores the basic theory and structure of a well-known neural network topology.
This is the first in a series of articles that will serve as a lengthy introduction to the design, training, and evaluation of neural networks. The goal is to perform complex classification using a Python computer program that implements a neural-network architecture known as the multilayer Perceptron.
You can find the rest of the Perceptron series here for your convenience:
- How to Perform Classification Using a Neural Network: What Is the Perceptron?
- How to Use a Simple Perceptron Neural Network Example to Classify Data
- How to Train a Basic Perceptron Neural Network
- Understanding Simple Neural Network Training
- An Introduction to Training Theory for Neural Networks
- Understanding Learning Rate in Neural Networks
- Advanced Machine Learning with the Multilayer Perceptron
- The Sigmoid Activation Function: Activation in Multilayer Perceptron Neural Networks
- How to Train a Multilayer Perceptron Neural Network
- Understanding Training Formulas and Backpropagation for Multilayer Perceptrons
- Neural Network Architecture for a Python Implementation
- How to Create a Multilayer Perceptron Neural Network in Python
- Signal Processing Using Neural Networks: Validation in Neural Network Design
- Training Datasets for Neural Networks: How to Train and Validate a Python Neural Network
What Is a Neural Network?
Neural networks are signal-processing tools that are loosely based on the structure of the human brain. They are typically associated with artificial intelligence (AI). I don’t like the term “artificial intelligence” because it is imprecise and reductive. If you define “intelligence” as the ability to rapidly perform numerical calculations, then neutral networks are definitely AI. But intelligence, in my opinion, is much more than that—it’s the sort of thing that designs a system that rapidly performs numerical calculations, and then writes an article about it, and then ponders the meaning of the word “intelligence,” and then wonders why human beings create neural networks and write articles about them.
Furthermore, artificial intelligence isn’t artificial. It is very real intelligence, because it is a mathematical system that operates according to the intelligence of the human beings who designed it.
Neural networks are software routines that can “learn” from existing data and efficiently solve complex signal-processing problems. They are interesting to study and experiment with, and in some cases they far surpass the capabilities of “normal” algorithms. However, they won’t eliminate world hunger, they can’t write good poetry, and I doubt that they will ever drive a car as safely as a human being who is both sober and not composing a text message.
What Is Perceptron?
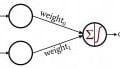
A basic Perceptron neural network is conceptually simple. It can consist of nothing more than two input nodes and one output node joined by weighted connections:

The dimensionality of the input data must match the dimensionality of the input layer. The term “dimensionality” can be a bit confusing here because most people can’t visualize something with more than three dimensions. All this really means is that your input data—for example, a pattern that you want to classify—is a vector with a given length, and your input layer must have a node for each element in the vector. So if you’re trying to classify a pattern represented by a series of 20 data points, you have a 20-element vector and need 20 input nodes.
An output node generates data that is of interest to the designer. The number of output nodes depends on the application. If you want to make a yes/no classification decision, you only need one output node, even if there are hundreds of input nodes. On the other hand, if the goal is to place an input vector into one of several possible categories, you will have multiple output nodes.
Data that move from one node to another are multiplied by weights. These ordinary scalar values are actually the key to the Perceptron’s functionality: the weights are modified during the training process, and by automatically adjusting its weights in accordance with the patterns contained in the training data, the network acquires the ability to produce useful output.
What Happens Inside a Node? (AKA How Do Neural Networks Work?)
The nodes in the input layer are just connection points; they don’t modify the input data. The output layer, as well as any additional layers between input and output, contain the network’s computational nodes. When numerical data arrive at computational nodes, first they are summed, and then they are subjected to an “activation” function:

The concept of activation goes back to the behavior of (biological) neurons, which communicate via action potentials that are either active or inactive; it’s more like an on/off digital system than an analog system. In the context of (artificial) neural networks, nodes—which are also called (artificial) neurons—can imitate neuronal behavior by applying a threshold function that outputs 1 when the input is greater than the threshold and 0 otherwise.
The following plot conveys the input–output relationship of the basic “unit step” activation function.
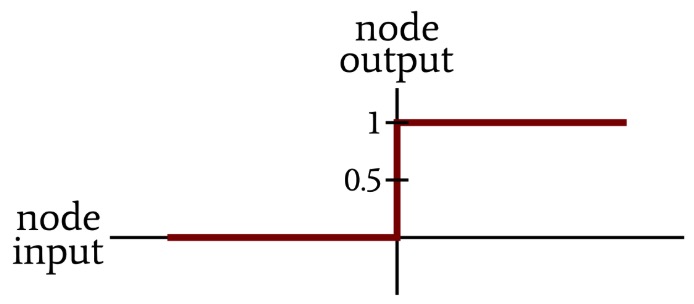
By inserting this threshold transformation into the propagation of data from node to node, we are introducing nonlinearity into the system, and without this nonlinearity a neural network’s functionality is very limited. The theory here is complex, but the general idea (I think) is that combinations of linear transformations, even if these linear transformations occur numerous times, will never be able to approximate the relationships that characterize complex natural phenomena and sophisticated signal-processing tasks.
Despite the fact that real neurons operate according to some sort of on/off model, the threshold approach to (artificial) neural network activation is not optimal. We’ll revisit this topic in a future article.
Conclusion
We’ve covered the most basic elements of the Perceptron, and in the next article we’ll put these pieces together and see how a rudimentary system works.
Neural networks are an expansive topic, and I’m giving you fair warning that this could be a long series. But I think that it will be a good one.
Related Content











Neat article. I think you should clarify this part:
“All this really means is that your input data—for example, a pattern that you want to classify—is a vector with a given length, and your input layer must have a node for each element in the vector. So if you’re trying to classify a pattern represented by a series of 20 data points, you have a 20-element vector and need 20 input nodes.”
It should be clear that the dimensionality refers to the data from a specific instant or sampling interval. Not the entire data set gathered. As it is, it seems “20 data points” refers to 20 rows in a table (for instance), as opposed to 20 *columns* in the same row.