Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinUnderstanding Local Minima in Neural-Network Training
This article discusses a complication that can prevent your Perceptron from achieving adequate classification accuracy.
In the AAC neural network series, we've covered a wide range of subjects related to understanding and developing multilayer Perceptron neural networks. Before reading this article on local minima, catch up on the rest of the series below:
- How to Perform Classification Using a Neural Network: What Is the Perceptron?
- How to Use a Simple Perceptron Neural Network Example to Classify Data
- How to Train a Basic Perceptron Neural Network
- Understanding Simple Neural Network Training
- An Introduction to Training Theory for Neural Networks
- Understanding Learning Rate in Neural Networks
- Advanced Machine Learning with the Multilayer Perceptron
- The Sigmoid Activation Function: Activation in Multilayer Perceptron Neural Networks
- How to Train a Multilayer Perceptron Neural Network
- Understanding Training Formulas and Backpropagation for Multilayer Perceptrons
- Neural Network Architecture for a Python Implementation
- How to Create a Multilayer Perceptron Neural Network in Python
- Signal Processing Using Neural Networks: Validation in Neural Network Design
- Training Datasets for Neural Networks: How to Train and Validate a Python Neural Network
- How Many Hidden Layers and Hidden Nodes Does a Neural Network Need?
- How to Increase the Accuracy of a Hidden Layer Neural Network
- Incorporating Bias Nodes into Your Neural Network
- Understanding Local Minima in Neural-Network Training
Neural-network training is a complex process. Fortunately, we don’t have to understand it perfectly to benefit from it: the network architectures and training procedures that we use really do result in functional systems that achieve very high classification accuracy. However, there is one theoretical aspect of training that, despite being somewhat abstruse, deserves our attention.
We’ll call it “the problem of local minima.”
Why Do Local Minima Deserve Our Attention?
Well … I’m not sure. When I first learned about neural networks, I came away with the impression that local minima really are a significant obstacle to successful training, at least when we’re dealing with complex input–output relationships. However, I believe that recent research is downplaying the importance of local minima. Perhaps newer network structures and processing techniques have mitigated the severity of the problem, or perhaps we simply have a better understanding of how neural networks actually navigate toward the desired solution.
We’ll revisit the current status of local minima at the end of this article. For now, I’ll answer my question as follows: Local minima deserve our attention because, first, they help us to think more deeply about what is really happening when we train a network via gradient descent, and second, because local minima are—or at least were—considered a significant impediment to the successful implementation of neural networks in real-life systems.
What Is a Local Minimum?
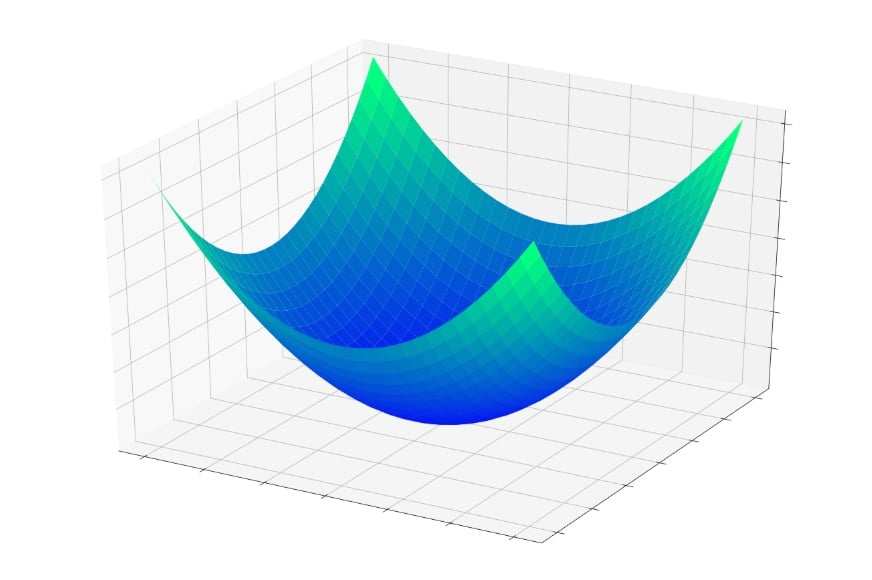
In Part 5, we considered the “error bowl” shown below, and I described training as essentially a quest for the lowest point in this bowl.
(Note: Throughout this article my images and explanations will rely upon our intuitive understanding of three-dimensional structures, but keep in mind that the general concepts are not limited to three-dimensional relationships. Indeed, we frequently use neural networks whose dimensionality far exceeds two input variables and one output variable.)
If you were to jump into this bowl, you would slide down to the bottom, every time. No matter where you begin, you will end up at the lowest point of the entire error function. This lowest point is the global minimum. When a network has converged on the global minimum, it has optimized its ability to classify the training data, and in theory, this is the fundamental goal of training: to continue modifying weights until the global minimum has been reached.
We know, however, that neural networks are capable of approximating extremely complex input–output relationships. The error bowl above doesn’t exactly fit in the “extremely complex” category. It’s simply a plot of the function \(f(x,y) = x^2 + y^2\).
But now imagine that the error function looks something like this:

Or this:

Or this:

If you jumped randomly into one of these functions, you would often slide down into a local minimum. You would be in the lowest point of a localized portion of the graph, but you may be nowhere near the global minimum.
The same thing can happen to a neural network. Gradient descent relies on local information that will, we hope, lead a network toward the global minimum. The network has no prior knowledge about the characteristics of the overall error surface, and consequently when it reaches a point that seems like the bottom of the error surface based on local information, it cannot pull out a topographical map and determine that it needs to go back uphill in order to find the point that is actually lower than all others.
When we implement basic gradient descent, we are telling the network, “Find the bottom of an error surface and stay there.” We’re not saying, “Find the bottom of an error surface, jot down your coordinates, and then keep hiking uphill and down until you find the next one. Let me know when you’re done.”
Do We Really Want to Find the Global Minimum?
It is reasonable to assume that the global minimum represents the optimal solution, and to conclude that local minima are problematic because training might “stall” in a local minimum rather than continuing toward the global minimum.
I think that this assumption is valid in many cases, but fairly recent research on neural-network loss surfaces suggests that high-complexity networks may actually benefit from local minima, because a network that finds the global minimum will be overtrained and therefore will be less effective when processing new input samples.
Another issue that comes into play here is a surface feature called a saddle point; you can see an example in the plot below. It’s possible that in the context of real neural-network applications, saddle points in the error surface are in fact a more serious concern than local minima.

Conclusion
I hope that you have enjoyed this discussion of local minima. In the next article, we’ll discuss some techniques that help a neural network to reach the global minimum (if indeed that is what we want it to do).